Was ist Data Mesh?
Data Mesh ist ein neues Architekturkonzept für das Datenmanagement in größeren Unternehmen. Entgegen der heutzutage üblichen Zentralisierung von Unternehmensdaten strebt der Data Mesh Ansatz eine zunehmende Dezentralisierung des „Dateneigentums“ an.
Das heißt: Die Verantwortung für die Daten liegt nicht bei einem spezialisierten Team von Data Engineers. Vielmehr verbleibt sie dort, wo ihr Ursprung liegt: in den Fachbereichen. Data Mesh ist also nicht nur eine techische Datenarchitektur, sondern ebenso ein organisatorisches Konzept.
Dabei ist die Zielsetzung, Engpässe in der Umsetzung von geschäftlichen Anforderungen zu überbrücken und somit Markteinführungszeiten und Innnovationsprozesse zu beschleunigen. Analysten und Data Scientists erhalten bei der Verwendung von Daten mehr Freiheit und Flexibilität. Aber auch fachliche Mitarbeiter werden dazu ermutigt, neue Wege mit Daten zu gehen und Lösungen in Eigeninitiative zu realisieren. Die Ergebnisse sind dann oftmals viel näher am Nutzer, als es beim Umweg über ein zentrales Daten-Team der Fall wäre. So ist der Datenarchitekturansatz einen guter Ausgangspunkt für den Weg zur Data Driven Company.
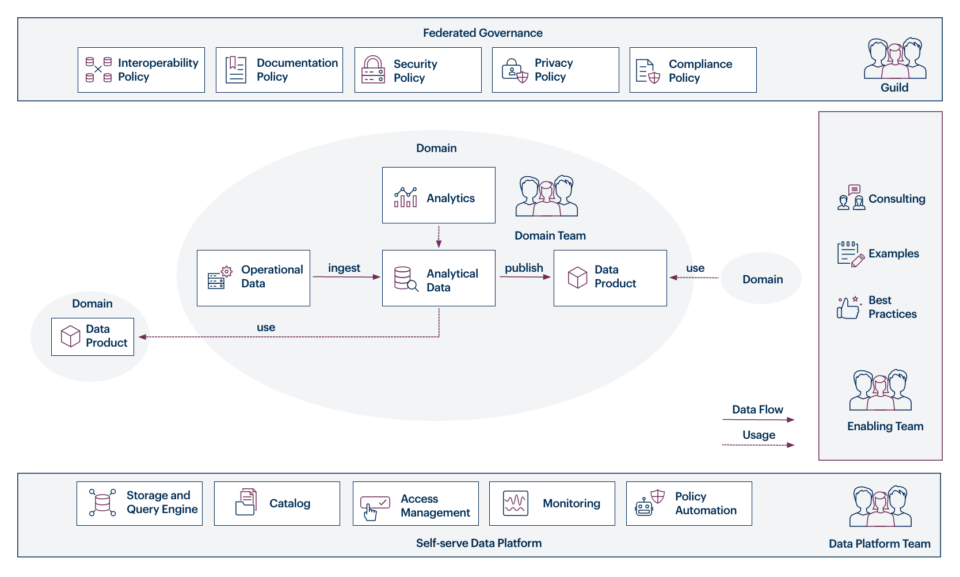
Die technologische Grundlage von Data Mesh Architekturen bilden moderne Cloud-Dienste. Hier finden sich einerseits Softwarelösungen, mit denen Anwender auch ohne Programmierkenntnisse sogenannte Datenprodukte entwickeln und mit anderen Teams teilen können. Andererseits lassen sich Speicher- und Rechenressourcen nach Bedarf skalieren, sodass Unternehmen ein schrittweiser Einstieg in das Thema ermöglicht wird. Nicht zuletzt existieren ausgereifte Services für die Umsetzung einer Governance und einem entsprechenden Data Catalog, die das Gesamtkonstrukt zusammenhalten.