11.10.2023 Jörn Ebbers
Snowflake or Databricks? This is a question many decision-makers of companies are confronted with when it comes to finding the right cloud platform for modernizing their data landscapes. Often, the answer to that question is Snowflake. Not surprising at all: According to the provider, the solution is supposed to be significantly more performant and cost-effective at the same time.
But is this really the case? In the following, I will tell you about a real world retail customer´s project situation that clearly refutes this argumentation, at least for the Power BI universe. In the scope of this project, a Proof of Concept (PoC) has shown that the key data communicated by Snowflake on its Query Engine were generated in a laboratory situation. What’s more is that the provider has also advertised the solution by using questionable comparisons with Databricks. If you “adjust” the relevant factors, results suddenly look completely different.
Before going into more detail, I will outline why the speed of data queries should be one of the key criteria when it comes to finding the right platform software.
Why is the query engine so important?
When comparing Databricks with Snowflake, the focus oftentimes is on features for the use of Artificial Intelligence (AI), Machine Learning and Real-Time Analytics. Both providers showed great development in these areas over the past years with both of them taking the lead by turns. The Query Engine on the other hand is an overlooked element, even though the performant direct data query is a core requirement for being a Data-Driven Company. Even more so, when future applications regarding AI or IoT are on the agenda.
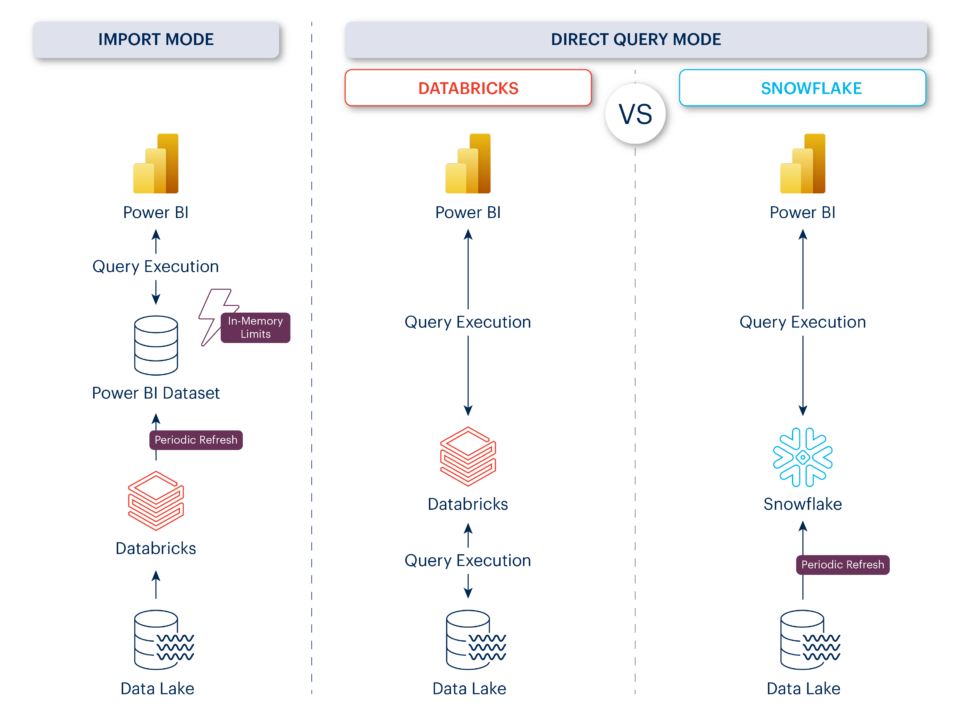
In this context, direct queries are also often preferable to data analysis via In-Memory storage, as offered in Power BI, for example. In my opinion, the reasons for this are as follows:
- Data Freshness guarantee: Anyone accessing the data directly can always rely on it being up to date. For In-Memory storage, guaranteeing consistently updated data is difficult, even for medium-sized datasets.
- Unlimited scalability: When processing datasets In-Memory, the limit is set at 400 GB. These limits do not apply to Direct Query Mode.
- Significant cost reduction: In-Memory delivers fast results, but it is also expensive. For example, with a storage capacity of 400 GB, you can expect monthly costs of more than €80,000.
In a nutshell: If you can live with certain compromises in response times, the Direct Query Mode is the most practical and cost-effective alternative in many use cases. But which solution is the real winner in this discipline? Databricks or Snowflake?
Snowflake questionable setup
Let’s come back to the practical case I mentioned at the beginning. During the project in question, I was able to see how a Snowflake team compared its own Query Engine with Databricks´s engine as part of a PoC. The results matched the vendor’s advertising promises: Snowflake is three times faster and reduces costs by 50 percent.
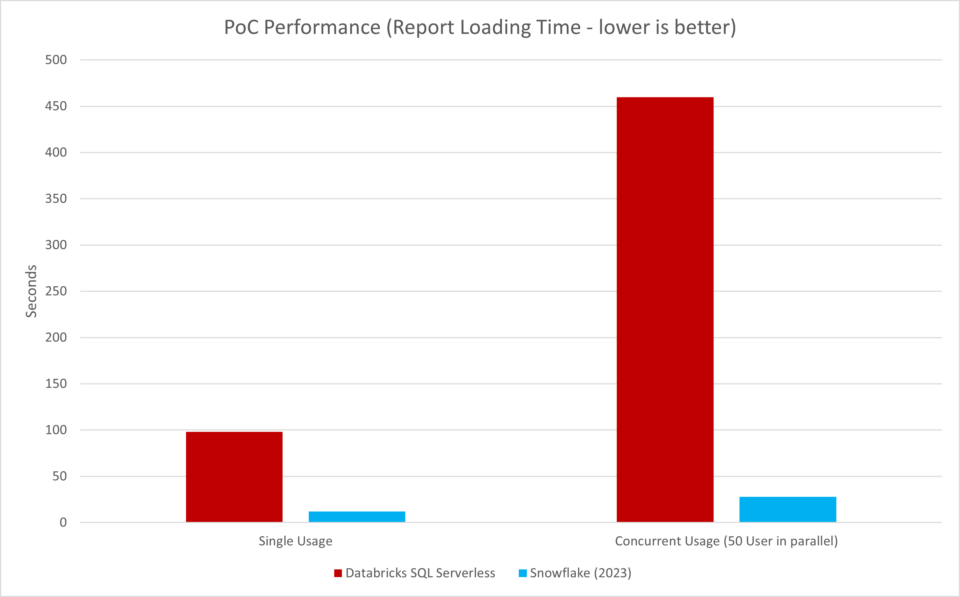
The results were too good to be true, since they did not match at all with the experiences that both I and all my DevLead colleagues had made in previous projects. I decided to revisit the PoC results. First, I took a closer look at the setup and came across two “peculiarities”:
- Outdated DAX query: For the query from the Power BI report, a “historically grown” DAX code was used, leading to inefficient processes when using Databricks and thus significantly increasing the query times. Snowflake interprets the existing DAX code differently, which ultimately results in the speed advantage.
- Outdated Databricks Runtime version: In fact, Databricks and Power BI versions from 2021 were compared with Snowflake and Power BI latest versions from 2023. The effect of this two-year difference in the development and innovations of cloud technologies should be quite clear to everyone.
Then I decided to update the DAX code, upgraded Databricks Runtime version and used the latest Power BI version – and there you go:
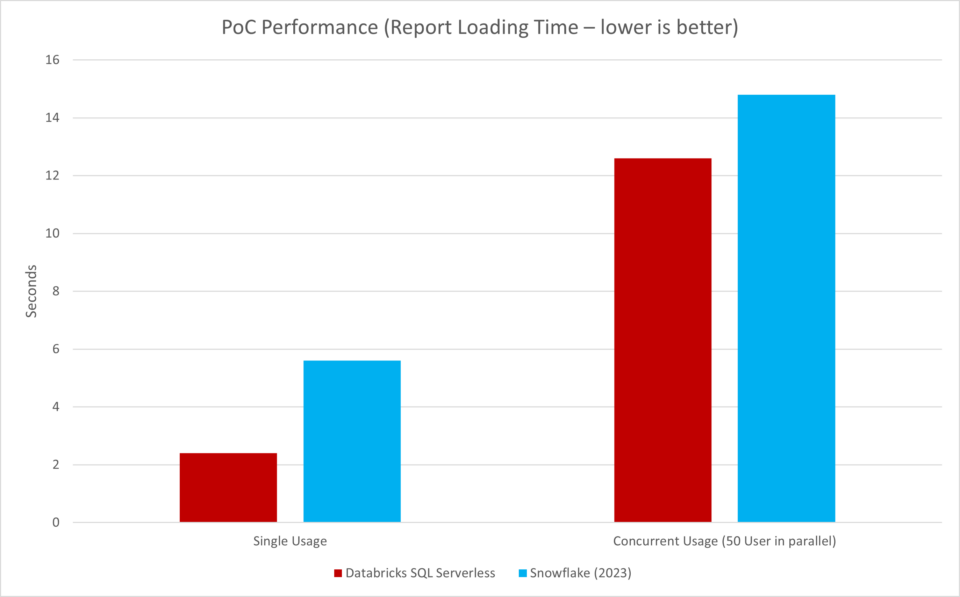
By taking a quick look at the Power BI report, you could see that Databricks is suddenly twice as fast as Snowflake. And even with parallel queries from 50 users, Databricks is clearly ahead! After these results, I obviously switched to the cost comparison with significiant curiosity.
Databricks is also much cheaper
For the record, during the PoC Snowflake claimed that the use of their engine has reduced costs by a whopping 50 percent:
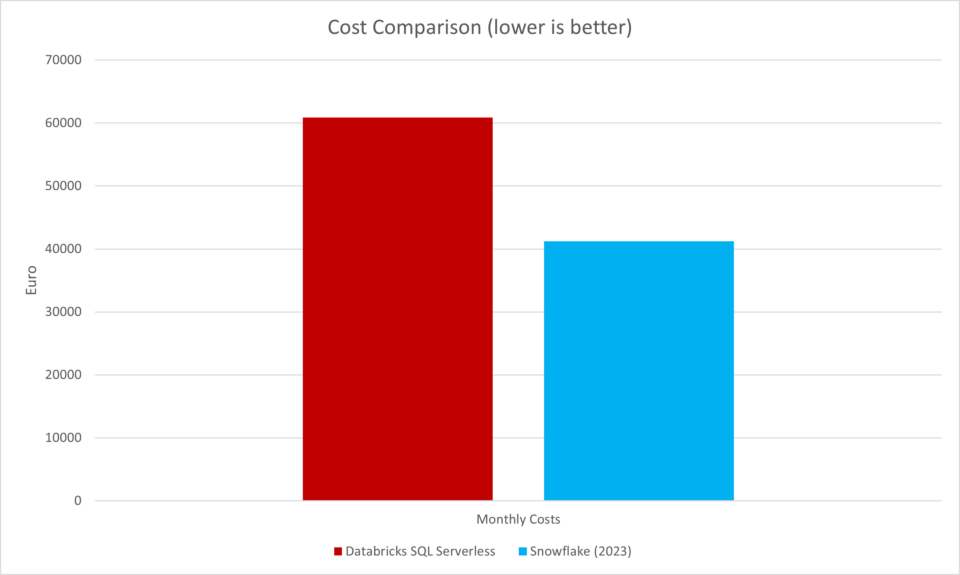
But how exactly was this amount calculated? In fact, the PoC was based on different scenarios here as well. As it turned out, a daily usage of 5 hours was estimated for the Snowflake Warehouse, while for Databricks, a 24/7 operation set the standard. According to the testers, this setup was because the Databricks Cluster „took a few minutes to spin up, whereas Snowflake Warehouse only takes a few seconds.“
What is there to say? Two years ago, this argument would have been valid but since the release of Databricks SQL Serverless at the latest, it has become obsolete. For this reason, I simply created identical scenario setup and set a runtime of 5 hours for the Databricks Cluster – here is the result:
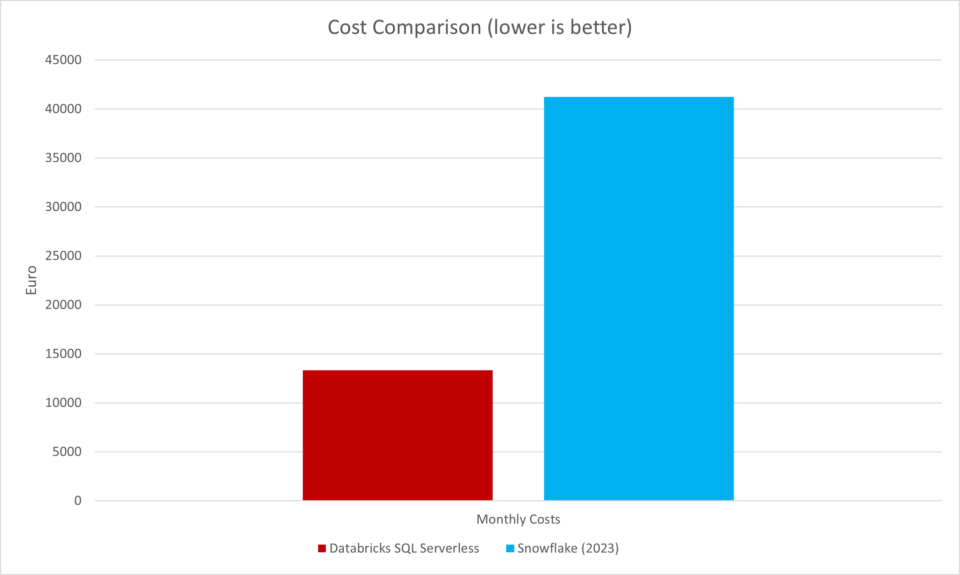
Remarkably, the cost for Databricks suddenly drops to only a third of what you would pay for Snowflake. In addition, we can clearly see that “Instant Scale” is no longer a strictly Snowflake unique selling proposition.
Conclusion: Snowflake compares apples with oranges
Now, did I perform a lot of optimizations on the Databricks side for my results that weren’t even necessary for Snowflake? I would definitely say, no. After all, only the underlying star schema of a fact table with about 100 billion rows was stored in a partitioned format – which, in my opinion, should be state of the art by now. I deliberately refrained from further optimizations, such as Z-ordering.
Meanwhile, I consider the methods used by the Snowflake team in this case to be more than questionable. One could easily say that they compared apples with oranges. And that can lead to expensive consequences because a migration to Snowflake does not come for free. On the contrary, it involves enormous costs and efforts. In this respect, I can only plead for a fair and well-founded exchange of arguments that enables organizations to make reliable decisions for their future. After all, that should always be the core objective of any legitimate consultancy.
Are you also looking to lead your enterprise-wide data analytics into the future with a modern cloud platform? Visit our Databricks Lakehouse page.
About the Author

Jörn Ebbers
Principal Consultant
Jörn Ebbers verantwortet für ORAYLIS die Planung und Umsetzung von unternehmensweiten Datenlösungen in der Cloud. Dabei liegt sein Fokus auf dem geschäftlichen Nutzen sowie anwenderfreundlichen Datenanalysen durch die Fachabteilungen.





Kommentare (0)