SQL Server 2005 | SQL Server 2008
Semi-additive measures are measures that don’t use the same aggregation method along all of the cube’s dimensions. In SSAS the time dimension plays an important role here. For example, if you choose the ‚AverageOfChildren‘ aggregation method, the measure is averaged over the time but summed up over all other dimensions. When do we need this? Well, usually semi-additive measures are used when working with snapshot data like stock levels, balances of accounts etc.
For an example, let’s look at a car park. We want to analyze the number of cars that are in one of our two park houses at a certain time. For our example we use a very simple fact table looking like this (I simplified the time to just 2 days, so imagine we’re counting the cars at 1pm):
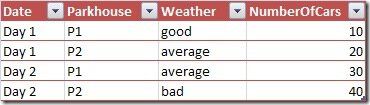
As you can see, someone also wanted to analyze the weather at each park house and each day so that we can easily see the effect the weather has on the parking behavior (obviously more people took the car when the weather was bad…).
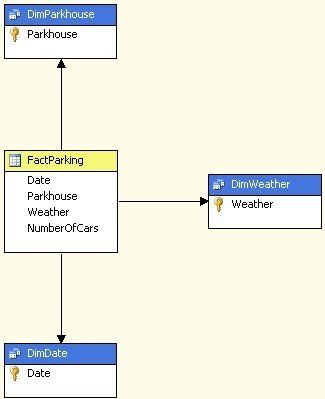
Based on the fact data above we use a very simple data model looking like this:
Now let’s do some analysis on that model. First we analyze by date and park house:
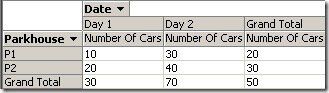
This clearly shows the semi-additive behavior of our measure: For each row (combining the two days) the value is averaged while it gets summed up across the park houses (columns) as expected. At day 1, 1pm we had 10 cars in car park P1. At the same time on day 2 there were 30. Of course we cannot add these values together but the average makes sense. So the meaning of the grand total is ‚at 1pm there was an average of 20 cars in our car park P1‘.
Now, what would happen if we start analyzing by the weather? As the weather is not our time dimension you might expect values to add up as a simple sum. So let’s try:

Hmm, what happened here? The sum would have been 75 but our OLAP query results in a value of 50. What had happened and what is the total? You can easily see that it is neither the sum nor the average of the above values.
In order to clarify this behavior, let’s also include the time in our analysis:
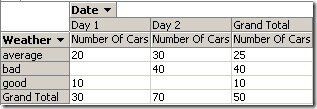
Using this view we can clearly see that SSAS made no mistake. The total number of cars being in our park houses at an average weather is 25 (average of 20 and 30, line one in the grid above), so this is correct. On the other hand, we had 30 cars in our park houses at day 1 (20 in a park house with average weather at that day and 10 in a park house with good weather) and 70 at day 2 giving a total average of 50. So this is also correct.
So the total for the weather is not the average or the sum of it’s detailed values but the average of the summed up values.
This is a very simple example of how semi-additive aggregation of a measure also influences aggregation against non-time dimensions as well.
With this in mind you are now well prepared to look at the following analysis based on the same source data:
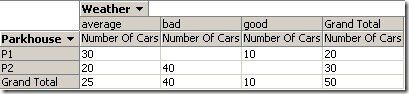
This time we left the time dimension completely out of the analysis resulting in averages along both other dimensions (park house and weather) as all values we actually see are already averages.
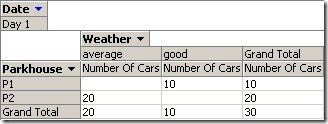
Surely, it’s less confusing when looking at a single point of time like in the example below, where everything sums up neatly:




Kommentare (0)