PDW v1/PDW 2012
In a previous post I briefly touched the question how to choose a good distribution key for a PDW distributed table. And also in this post I promised to get back to this topic in more detail later. The distribution key is a data base table column used to determine the distribution on the compute nodes. This is shown in the following illustration from my previous post , where 6 fact rows are distributed on two compute nodes based on the values in the date column.
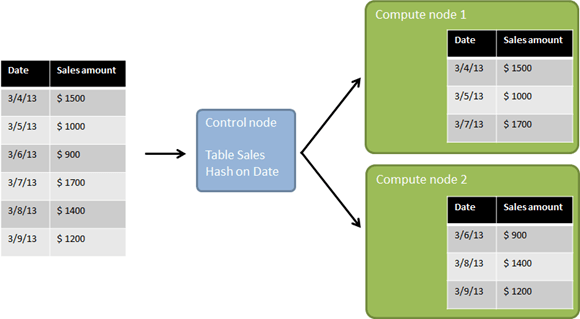
The table DDL statement would look somewhat like this:
-
CREATE TABLE [Sales].[dbo].[FactSales]
-
(
-
[Date] date NOT NULL,
-
[Sales amount] MONEY NOT NULL
-
)
-
WITH (DISTRIBUTION = HASH ([Date]));
The values in the distribution key column (Date column in my example) are mapped to the distribution using a hash function. The hash function is not a simple round-robin, but takes into account the number of compute nodes and the column’s data type (for example int is hashed differently compared to bigint) and can (currently) not being queried directly. If a scale unit is added to the PDW (therefore bringing more compute nodes into the appliance) the existing data is redistributed and the internal hash function then takes the new nodes into account (different hash values).
One more thing to notice before we look at considerations for the distribution key column is that the distribution is not only happening on the compute node level, but the data is also distributed within each of the compute node. Each logical table of the data model becomes 8 tables (postfixed with letter a to h) on each of the compute nodes to support different file groups. Don’t confuse this with table partitions. Table partitioning works on top of this. So, assuming you have 10 compute nodes, a single distributed table (logical database view) with 10 partitions becomes 800 physical partitions (each of the 8 distributed tables per compute node with 10 partitions giving 80 partitions, multiplied by the number of compute nodes). Fortunately enough, PDW takes care about all that fully automatically. You just have to create those 10 partitions on the original table. PDW does the magic behind.
So, after this short introduction, let’s get back to the question, what we need to consider in order to find a good distribution key. Please note that I’m saying ‘considerations’, not recommendations or guidelines. The reason is that depending on your data and your typical query work load, you should consider the topics below to find a good solution for yourself.
Consideration 1.: Skew
We’re using the term skew here to describe the situation where some distributions contain much more or much less data than the average of the distributions. If typical queries involve a large number of rows, the power of the PDW depends on the ability to parallelize the query to its nodes. In the worst case, if all the data sits on only one compute node, PDW behaves much like an SMP machine. Depending on the structure of the query (see considerations 2 and 3), the “slowest” compute node sets the time for the query to complete. So, we want all compute nodes to contain about the same amount of data to get the most out of the PDW (not much skew).
You may notice however that I mentioned the query behavior (large number of rows involved). This topic is extremely important and I’m getting back to this with Consideration 4.
Usually, to prevent skew, you would look for an equally distributed column with many distinct values. In my example from above, I used Date as the distribution column. Is this a good idea? Assuming that you have different buying behavior depending on the season, it might lead to a significant skew. So date might not be a good column to base your distribution on. Usually good candidates are fields like order number, transaction number, any kind of sequential counters etc.
In order to show the effect, I’m using a table FactSales with about 9 million rows on a PDW with 2 compute nodes (giving 16 distributions). First, I’m going to distribute the data based on the order number. In order to see how the distribution works, we’re using the PDW_SHOWSPACEDUSED function:
-
DBCC PDW_SHOWSPACEUSED(„dbo.FactSales„)
Here is the result:
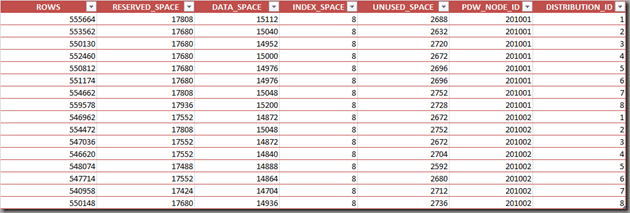
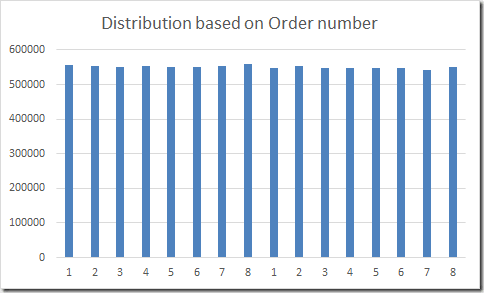
The compute node can be found in the next to last column (PDW_NODE_ID). The distribution number on the compute node itself is shown in the last column (1-8 per compute node). As you can see, the distribution (rows, first column) is quite balanced. Here’s how it looks when plotted over the distributions:
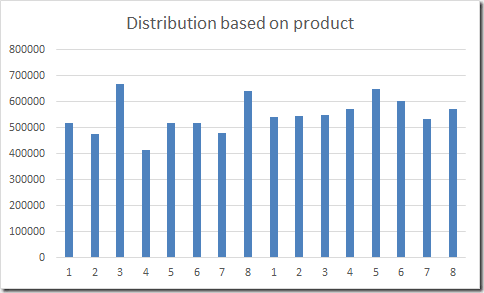
Next, let’s distribute the same data based on the product. Since some products are sold more often than others, we expect some skew to occur. And for the (real life) data I used here, this is true as you can see from the following visualization:
My data also contains the line number (per order). I expect this to be a very bad distribution key because I don’t have many orders with more than 30 order lines. So, here is the distribution per line number:
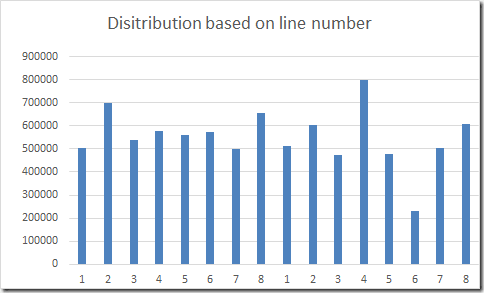
In this case, you can see significant skewing effect. The number of rows in distribution 4 (node 2) is 4 times the number of distribution 6. I even expected the distribution to be worse, since the distribution of the order line column has a significant skew. Here’s a histogram of the order line column:
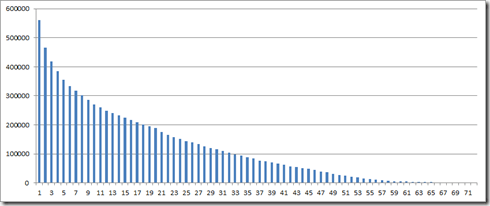
So, you see, that the build-in hash function of the PDW does a great job. However, if you want to reduce skew in order to leverage the full parallel power of the PDW for queries involving a large amount of rows, make sure to choose a column with equally distributed values. Usually you’re looking for a column with a lot of distinct values. As you can imagine, if your distribution key column has less distinct values than the number of distributions, you’ll end up with some distributions having no data at all (bad choice).
Consideration 2: Distribution compatible queries (joins)
For parallelization, our goal is that each node can work on the query independently. For more complex queries however, it becomes necessary to shuffle data between the nodes. When looking at the distribution compatibility of queries, we try to optimize the need for shuffling data between the nodes. In general, a query is distribution compatible if the data resulting from right side of the join sits on the same node as the data resulting from the left side of the join. For a normal SMP machine this is always true, but for distributed tables, if the distribution on the left and right side of the join is based on different criteria, it’s getting more complicated.
First, let’s take a look at a star join, where the join destinations are replicated tables.
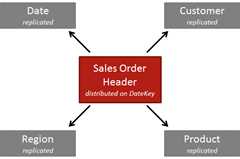
In this case we’re joining a Sales Order Header table to it’s dimension. All dimensions are replicated tables here, so no matter on which column we’re distributing the Sales Order Header table, we’re always sure to find the matching data on the same node (as the data is available on every node, distribution of the Sales Order Table doesn’t matter in this case).
Now, let’s assume we’re joining the Sales Order Header table (distributed on DateKey) with its Sales Order Detail rows (distributed on DateKey). The join column is the OrderNumber. Now for a given row of the Sales Order Header table the PDW cannot be sure that corresponding rows of the Sales Order Detail table are located on the same node as they’re distributed based on the DateKey, not on the OrderNumber. This causes shuffle move operations in order to get both sides being aligned on their join condition.

Anyway, in this practical case, we know that the rows are on the same machine as each order number refers to an order of a specific date. So one order cannot have two different dates. But this is implicit knowledge that is not available to the query optimizer in order to find a good query plan.
So, in order to get a distribution compatible join between these two tables, we could either
- distribute both tables on the OrderNumber (which makes sense, since both tables will frequently being queried using this column as a join criteria)
or - Include the DateKey in the column-list for the join (this is an option for views or for the Data Source View of an SSAS database for example)
By including the distribution key in the column list for the join we’re letting PDW know, that the grain of the join is truly finer than the distribution, so it can process each the join-operation on each node separately.
But wait, we talked about considerations for the distribution key of the data base table and now we’re looking at queries and joins. But this is right, the decision for the distribution key depends a lot on the expected work load and on the question which queries you like to support best with your distribution architecture. I’m getting back to this in consideration 4 later.
To be continued with the next post.


Kommentare (0)