Dimensional modeling
Tracking historical changes within a dimension is a common task in data warehousing and well covered by Ralph Kimball’s slowly changing dimension (SCD) methods. In short, the SCD methods proposed by Ralph Kimball assume, that the source system (for example the ERP system) doesn’t keep historical versions of its data records, so changes need to be detected at the time when data is loaded into the warehouse. To keep historical values, versions of the master data records are created to memorize each state of the original record together with a valid from/to timestamp so that fact data can be joined to corresponding dimension data. But the valid from/to dates are usually not a good idea for joining fact data to the associated dimensions because this would result in range lookups (ETL) or date range (between) joins (in SQL or ELT). The surrogate key concepts offers a good solution here, by assigning a unique key (the surrogate key) to each version of a record. Now, this key can be used as a direct inner join from the fact table to its dimensions. This approach moves the time consuming process of resolving date ranges from query time to data loading time, so it has to be performed only once. Query performance now benefits from the simplified link structure between the tables.
However, there may be some cases, where you find valid from/to dates in the original source system. In this case, the historical values are provided by the source system and usually it’s not necessary for the data warehouse to track the changes. While this sounds to be much more simple than the case with missing validity dates, it’s usually a challenging situation, especially when past records (and their valid from/to dates) may be modified. For example, a given date range could be split or merged or the from and to dates may shift. In either case, the surrogate keys of some fact rows would point to the “wrong” dimension record afterwards. So, for these cases you will need to periodically reload parts of your data warehouse (for example the last three months) or in some rare cases track the changes and adjust the surrogate keys of the fact tables. I’m saying rare cases as update-operations on fact tables that are tuned for high volume bulk loads and bulk queries are usually not a good idea, so you may want to implement a partition-wise recreation of the fact table (partition switch operations) which adds some complexity to the overall workload management.
However, after this intro my post today is about a situation where you have several linked tables in the source system, all with a valid from/to date. You may find this situation for example in SAP’s human resources tables where the properties of an employee are stored in so called info types which are independently versioned by valid from/to date ranges. In this post, I’m using a much more simplified scenario with the following 4 tables:
Employee

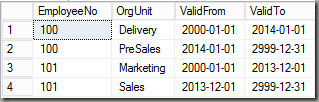
Organizational Unit (OrgUnit)
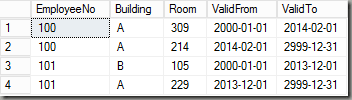
Location
Company Car (Car)
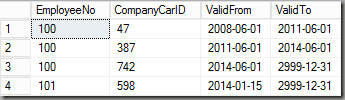
The tables reflect a very simple human resources model of four tables, a base table Employee and three detail tables, all joined by the EmployeeNo-field. Each table may contain multiple versions of data and therefore each table has valid from/to fields to distinguish the versions. In my example I’m using the approach of an including ValidFrom and an excluding ValidTo. If you take a look at the first two rows of the OrgUnit table for example, this means that employee 100 was in the organizational unit “Delivery” from Jan 1, 2000 until December 31, 2013 and then starting with January 1 2014 in “PreSales”.
For each of the four tables, EmployeeNo together with ValidFrom forms a primary key.
One potential problem with such data is that since valid from/to are delivered from the source system, we need to make sure that these date ranges do not overlap. There might be scenarios where you need to deal with overlapping date ranges (for example, an employee may have none, one or many phone numbers at a given point in time, for example a cell phone and a land line). If you need to model such cases, many-to-many relations between fact and dimensional data may be a solution or you could move the information from the rows to columns of the new dimension table. But for this example, I will keep it simple, so we don’t expect overlapping data in our source tables.
However, it’s always a good idea to check incoming data for consistency. The following query for example checks if there are overlapping date ranges in the Employee table by using window functions to retrieve the previous and next date boundaries:
-
select * from (
-
select
-
EmployeeNo
-
, [ValidFrom]
-
, [ValidTo]
-
, lag([ValidTo],1) over (partition by [EmployeeNo] order by [ValidFrom]) PrevValidTo
-
, lead([ValidFrom],1) over (partition by [EmployeeNo] order by [ValidFrom]) NextValidFrom
-
from Employee
-
) CheckDateRange
-
where (PrevValidTo is not null and PrevValidTo>ValidFrom) or (NextValidFrom is not null and NextValidFrom<ValidTo)
Please note, that this query does not check for gaps but only for overlapping date ranges in a table. If you like to detect gaps too, you’ll need to change the > and < in the where condition to a <>, i.e.
-
…where (PrevValidTo is not null and PrevValidTo<>ValidFrom) or (NextValidFrom is not null and NextValidFrom<>ValidTo)
Running this check on all the four tables from above shows that the data is consistent (no faulty rows returned from the query above).
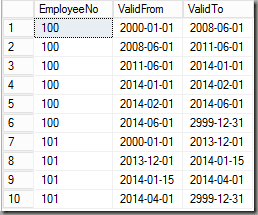
Next, we can start to combine all of the four tables to a single dimension table. Let’s first show the final result:
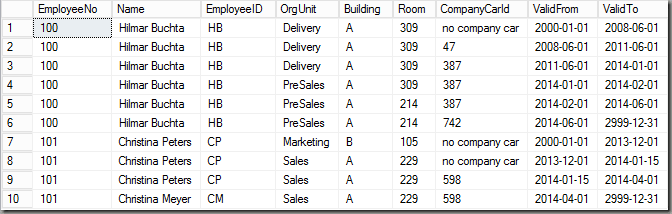
The information of the four tables is now combined into a single table. Whenever an attribute changes this is reflected by the valid from/to date range. So for example, the first change for employee 100 was the company car at June 1, 2008.
So, how do we get there? At first, as the resulting valid from/to dates need to reflect all date ranges from all of the four tables, I start by collecting all of those dates:
-
with
-
ValidDates as
-
(
-
select EmployeeNo, ValidFrom as Date from Employee
-
union
-
select EmployeeNo, ValidTo from Employee
-
union
-
select EmployeeNo, ValidFrom from OrgUnit
-
union
-
select EmployeeNo, ValidTo from OrgUnit
-
union
-
select EmployeeNo, ValidFrom from Location
-
union
-
select EmployeeNo, ValidTo from Location
-
union
-
select EmployeeNo, ValidFrom from Car
-
union
-
select EmployeeNo, ValidTo from Car
-
)
This gives a list of all valid from/to-dates by employee from all of the four tables with duplicates being removed (since I used a union, not a union all). This is how the result looks like:
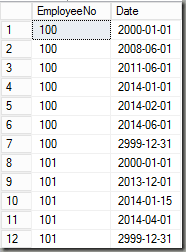
Next, I’m using this information to build the new valid from/to date ranges by using a window function to perform a lookup for the next date:
-
with
-
ValidDates as …
-
,
-
ValidDateRanges1 as
-
(
-
select EmployeeNo, Date as ValidFrom, lead(Date,1) over (partition by EmployeeNo order by Date) ValidTo
-
from ValidDates
-
)
-
,
-
ValidDateRanges as
-
(
-
select EmployeeNo, ValidFrom, ValidTo from ValidDateRanges1
-
where ValidTo is not null
-
)
Please note, that we already have the 10 resulting rows from the final result (see above) with the correct date ranges but without information from our four tables yet. So, now we can join the four tables with the date range table making sure to include the proper date range in the join condition. Here’s the resulting query:
-
with
-
ValidDates as …
-
, ValidDateRanges1 as …
-
, ValidDateRanges as …
-
-
select
-
E.EmployeeNo
-
, E.Name
-
, E.EmployeeID
-
, isnull(OU.OrgUnit,‚unknown‘) OrgUnit
-
, isnull(L.Building,‚unknown‘) Building
-
, isnull(L.Room,‚unknown‘) Room
-
, isnull(C.CompanyCarId,’no company car‘) CompanyCarId
-
, D.ValidFrom, D.ValidTo
-
from Employee E
-
inner join ValidDateRanges D
-
on E.EmployeeNo=D.EmployeeNo and E.ValidTo>D.ValidFrom and E.ValidFrom<D.ValidTo
-
left join OrgUnit OU
-
on OU.EmployeeNo=D.EmployeeNo and OU.ValidTo>D.ValidFrom and OU.ValidFrom<D.ValidTo
-
left join Location L
-
on L.EmployeeNo=D.EmployeeNo and L.ValidTo>D.ValidFrom and L.ValidFrom<D.ValidTo
-
left join Car C
-
on C.EmployeeNo=D.EmployeeNo and C.ValidTo>D.ValidFrom and C.ValidFrom<D.ValidTo
Since we made sure that no date ranges are overlapping within a single table, the joins can only return at most one row per employee and date range. To deal with gaps (for example in the car table) I used the isnull-function here to replace the gaps with a meaningful value (for example ‘no company car’ or ‘unknown’).
One final remark: In most cases, the source tables may contain many more fields that are not relevant for the data warehouse. However, the valid from/to information reflects changes within these fields too. The above approach would result in more than necessary versions in this case. However, as long as your dimension does not get too big, this is not really bad. On the opposite, if you later decide to include more information from the source tables, you already have properly distinguished versions for this information so you do not need to correct fact rows afterwards. This could even make it a good idea to include valid from/to dates from other associated tables even if no other information from those tables is yet being used in the data warehouse.
But if your dimension gets too big with this approach, you could always ‘clean’ unnecessary version using a simple group-by select with min(ValidFrom) and max(ValidTo) grouping by all other columns.
So, this showed how to combine multiple tables into a single dimension. As mentioned above, you still need to create surrogate keys and if you cannot eliminate the need for past data changes, you will also need to handle.





Kommentare (10)