In a Data Vault Model, Business Keys are used to integrate data. A Hub Table contains a distinct list of Business Keys for one entity. This makes the Hub Table the „Key Player“ of the Data Vault Data Warehouse. This blog post explains the pattern for loading a Hub Table. Moreover I will explain the differences between Data Vault 1.0 Hub Loads and Data Vault 2.0 Hub Loads.
Data Vault 1.0 Hub Load
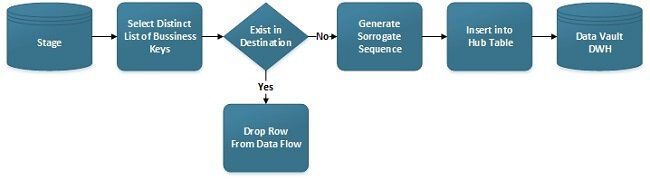
The function of a Hub Load is to load a distinct list of new Business Keys into the Hub Table. In Data Vault 1.0 it also generates a Sequence as Surrogate Key. Previously loaded Business Keys will be dropped from the Data Flow.
Example
To explain Hub Loads I am using a well-known example from the Adventure Works 2012 Data Base. The example load is supposed to load product information into the Data Vault Model.
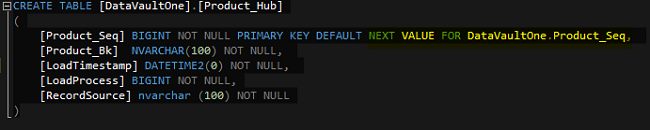
The destination table Product_Hub has the following structure.
Column Product_Seq
Surrogate Key for the Product
Column Product_Bk
Business Key of the Product – In this case we use the Product Number. Hub Tables have at least one column for the Business Key. When composite Business Keys are needed there can be more.
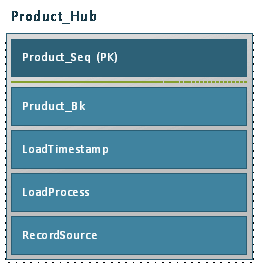
Column LoadTimestamp
Time of the Load – This column indicates the data currency.
Column LoadProcess
ID of the ETL Load that has loaded the record
Column RecordSource
Source of the Record – At least it needs the source system. But also you can add more specific values like the source table. The column could also contain the name of a business unit, where the data was originated. Choose what suites your requirements.
The Data Source is the table Product.Product. This data will be loaded without any transformation into the Stage Table Product_Product_AdventureWorks2012. The Stage Load is performed by a SQL Server Integration Services Package.
Product (Source Table) >> Product_Product_AdventureWorks2012 (Stage Table)
From the Stage, the Hub Load Pattern is used to load the data into the destination table.
Product_Product_AdventureWorks2012 (Stage Table) >> Product_Hub (Destination Table)
The following T-SQL and a SSIS implementations will illustrate the concept of Hub Loads.
T-SQL – Implementation
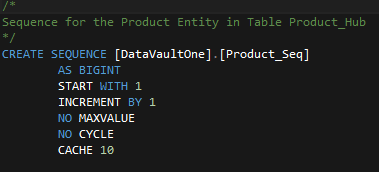
In this example a stored procedure Load_Product_Hub represents the Hub Load Pattern. To generate the Surrogate Sequence Number, the procedure is using a SQL Server Sequence.
Creating a Sequence in T-SQL
The stored procedure Load_Product_Hub shows how the load pattern could be implemented in T-SQL.
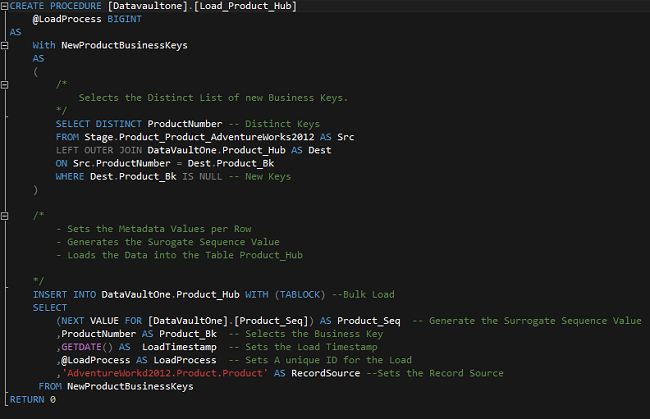
The command NEXT VALUE FOR gets the new Sequence Number for each row.
SQL Server Integration Services – Implementation
When we model Data Warehouse Loads, we want to use an ETL Tool like Microsoft SQL Server Integration Services.
This sample shows how the pattern can be implemented in Integration Services.
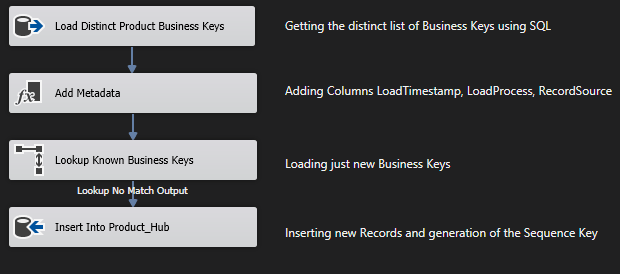
Generation of a Surrogate Sequence Key when using Integration Services
There are many ways to generate keys within SSIS. You can write your own Key Generator in C# or apply a 3th Party Vendor – Generator. The database itself has some capabilities to generate keys. It is common to use an Identity Column to generate keys. But if you truncate the table the Identity Column will be reset. This can depending on your ETL Architecture cause duplicate key issues.
Recommendation
To avoid this behavior I recommend using a Sequence in a Default Constrain on the destination table. The benefits of a Sequence is that you do not have to deal with Key Generation within your ETL. Leave this task to the database. Keys are independent from the loading process. This makes it possible to exchange the ETL Process or the ETL Tool if that is necessary. The Sequence keeps incrementing also when the table gets truncated.
Using the Sequence as a Default Constrain on the destination table
Every new row will get a new Sequence Number by default. But still you can set the value within your ETL Process, if that is needed.
Data Vault 2.0 Hub Load
The main difference between a Hub Load in Data Vault 1.0 and Data Vault 2.0 are Hash Keys.
Hash Keys are a controversial topic. It is true that collisions can occur when using Hash Keys. On the upside, using Hash Keys can solve issues with late arriving data. More importantly they can increase the load performance of the data model significantly. They enable to load the data full parallel into the Data Vault Model. This can be achieved because the Business Keys are the base for the Hash Keys.
But pros and cons of Hash Keys should not be the matter of this article. In later posts we will investigate how Data Warehouse Loads can benefit from Hash Keys.
The load pattern for loading a Data Vault 2.0 Table is basically the same like in Data Vault 1.0. Just the Surrogate Sequence Key Generator gets replaced by a Hash Generator. 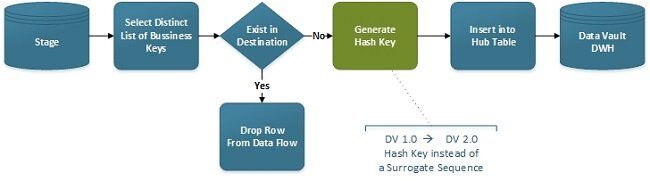
In Data Vault 2.0 Hash Keys replacing sequence keys. Therefore we have to modify our data model a little. The Product_Seq column has to be replaced by a column Product_Hsk. Using different suffixes here helps to differentiate Data Vault 1.0 and Data Vault 2.0 tables. The Data Type of the column has to be changed as well. It is recommended to use a Char (32) field to store a MD5 Hash Key.
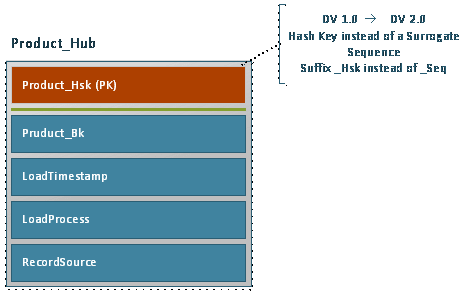
T-SQL – Implementation
Generating a MD5 Hash Key in T-SQL
To implement the modified Hub Load Pattern a Hash Key Generator is needed. In T-SQL I have implemented a custom function that returns the Hash Key of a given Business Key. The function is using the SQL Server HASHBYTE function to generate the Hash Key. 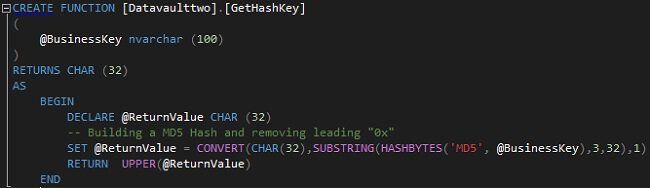
In the Procedure Load_Product_Hub the “SQL Server Sequence – Call” has been substituted by a call of the new Hash Generator function “GetHashKey”. 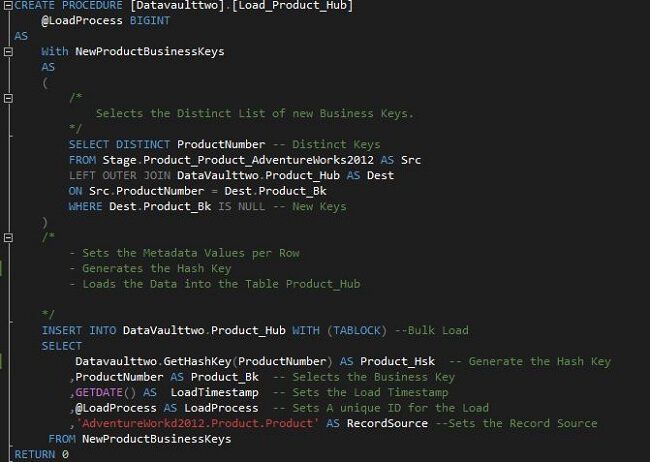
SQL Server Integration Services – Implementation
In SSIS the Data Flow Task has to be extended by a Script Component that generates the Hash Key. 
Generating a MD5 Hash Key in Integration Services
Within the Data Flow Script Component “Generate Hash Key” I added the following C# script. 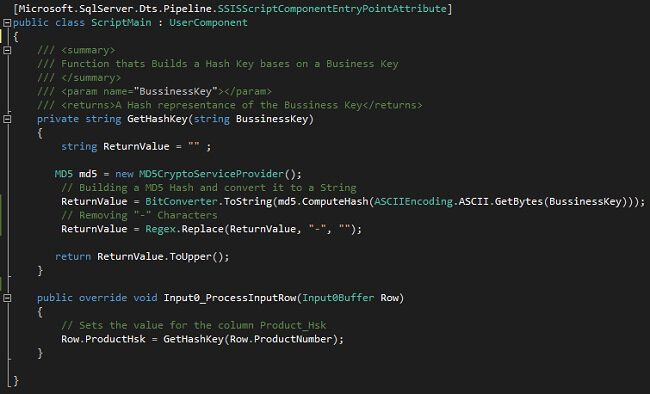
The script is using the System.Security.Cryptography.MD5CryptoServiceProvider to build the MD5 Hash.
Conclusion
The shown implementations are examples to explain how a Hub Load works. Each individual project will require individual implementations of these patterns.
A Hub Load is a simple pattern, which can be easily repeated for every entity in the data model. This is one reason, which makes the Data Vault Model so scalable.
Because Data Vault Loads are standardised, they can be generated and developed with a high degree of automation. As a result, Enterprise Data Warehouse Projects can be developed more agile and fast.
Sources: Dan Linstedt , Data Vault 2.0 boot camp class.



Kommentare (0)