Im Juli hat Microsoft ein komplett neues, von ursprünglichen Excel-Addins unabhängiges, Power BI Produkt auf den Markt gebracht. Wir haben darüber bereits berichtet (). Das neue Power BI vereint Power Query, Power Pivot und Power View in einer selbständigen Anwendung. Mit Power BI kann der Nutzer diverse Datenquellen abrufen (Power Query), die so gewonnenen Daten erweitern und modellieren (Power Pivot) und ansprechend visualisieren (Power View).
Power BI glänzt als Self-Services-Tool vor allem in den Bereichen Datenextraktion und Datenmodellierung. Das Reportingtool von Power BI ist zwar Chic anzuschauen, leider mangelt es dort aber an teilweise grundlegenden Funktionen wie z.B. , das Anzeigen der Top N Datensätze oder das Erstellen einer Rangordnung, welche die Reporting-Werkzeuge, wie Reporting Services und Excel-Pivot, beherrschen. Zwar ist es schade, dass diese Funktionen bisher fehlen, aber mit ein paar kleinen DAX-Formeln, ist es dennoch möglich Rangordnungen zu erstellen. Im Folgenden zeige ich anhand eines Probedatensatzes exemplarisch wie sich Rangordnungen mit DAX realisieren lassen. Dabei gehe ich auch darauf ein, wie man mit nicht eindeutigen Spalten in den Lookup-Tables umgehen kann.
Aufbau der Testdatenbank
Der Testdatensatz enthält 3 Tabellen (Verkauf, Kunde und Produkt), wie in Abbildung 1 dargestellt. Die Tabellen ‚Produkt‘ und ‚Kunde‘ enthalten generische Daten. Ein Kunde hat hierbei einen [Kundennamen] und gehört zu einem übergeordneten [Konzern], wobei der [Konzern] auch das Unternehmen selbst sein kann, siehe Abbildung 2. Die einzelnen Datensätze in ‚Kunde‘ können entweder über den Primärschlüssel [id_Kunde] oder über eine Kombination der anderen 3 Spalten (Kundenname, Konzern und Ort) eindeutig voneinander unterschieden werden. Für die späteren Formeln ist es wichtig anzumerken, dass einzelne Spalten nicht eindeutige Inhalte enthalten, z.B. gibt es mehre Kunden mit dem Namen „ABC“, die sich im selben [Konzern] „ABC“ befinden. Lediglich durch Hinzunahme der Spalte [Ort], lassen sich die beiden Datensätze unterscheiden. Die Tabelle ‚Produkt‘ ist etwas klarer strukturiert, da zumindest jeder Produktname [Produkt] eindeutig ist, das Attribut [Farbe] hingegen ist nicht zwingend eindeutig, siehe Abbildung 3. Die Verkaufstabelle ist ebenfalls sehr einfach, jeder Verkauf beinhaltet nur einen Artikel, siehe Abbildung 4.
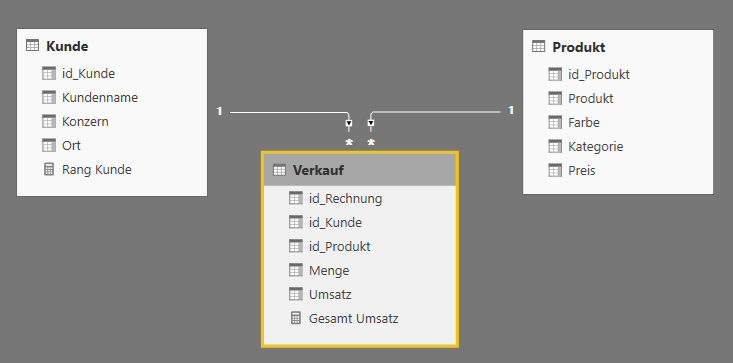
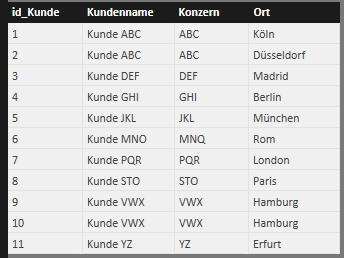
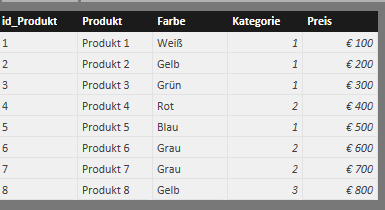
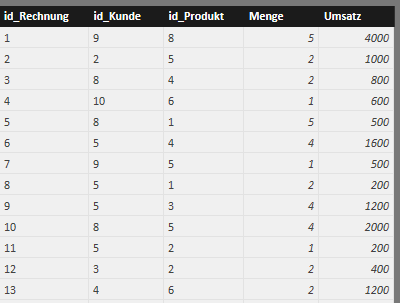
Vergeben von Rängen mit RANKX
Kommen wir zum Thema Rang. DAX besitz die Funktion RANKX.
-
(<table>, <expression>[, <value>[, <order>[, <ties>]]])
Für diesen Beitrag sind nur die ersten beiden Parameter relevant <table> und <expression>. Dem Parameter <table> muss eine Tabelle oder eine Spalte übergeben werden. Über die Elemente in dieser Tabelle erstellt RANKX den Rang. <expression> beschreibt auf welcher Berechnung die Rangordnung beruht. Wir wollen für jeden Kunden jetzt den jeweiligen Rang entsprechend seines Umsatzes ermitteln. Als erstes erzeugen wir ein einfaches Measure, dass wir im Folgenden für die Errechnung des Ranges benutzen.
Gesamt Umsatz =SUM([Umsatz])
Nun erzeugen wir den Rang auf Grundlage von [Gesamt Umsatz]. Wichtig ist hierbei einen Tabellen Ausdruck zu übergeben. Hierfür bietet sich All() an, welcher alle Inhalte aus der Tabelle Kunde, unabhängig vom Nutzer gesetzten Filter, zurückgibt.
-
Rang Kunde =RANKX(All(‘Kunde‘);[Gesamt Umsatz])
Wir erstellen einen einfachen Bericht, der [Kundenname],
[Gesamt Umsatz] und [Rang Kunde] zusammenbringt.
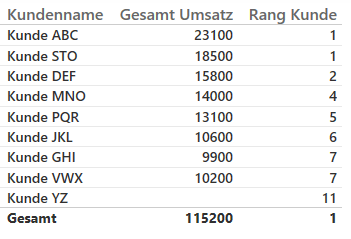
Offensichtlich ist etwas schiefgegangen, zwar wurden Ränge vergeben, allerdings erscheinen diese nicht besonders sinnvoll, z.B. ist der Rang 1 doppelt vergeben obwohl [Gesamt Umsatz] beim Kunden „ABC“ höher ist als bei „STO“. Wie kann so etwas passieren ?
Das Problem der nicht eindeutigen Spalteninhalte
Wie am Anfang erwähnt enthält die Tabelle Kunde einzigartige Datensätze, zumindest, wenn man den Primärschlüssel betrachtet. In unserem Bericht wurde hingegen die Spalte [Kundenname] abgefragt, welche nicht eindeutige Werte enthält. Die RANKX-Funktion benötigt aber eine eindeutige Attributsspalte als Ordnungsmerkmal. Ansonsten kommt es zu doppelt vergebenen Rängen oder fehlerhaften Rangfolgen.
Einfache Lösung für das Rangproblem
Eine mögliche Lösung ist den Primärschlüssel ([id_Kunde]) hinzuzuziehen, siehe Abbildung 6
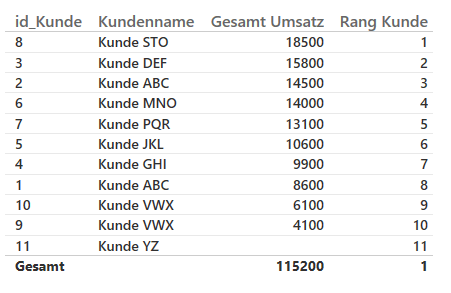
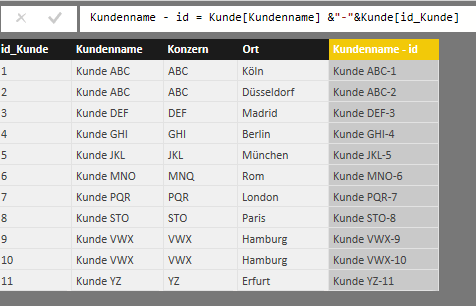
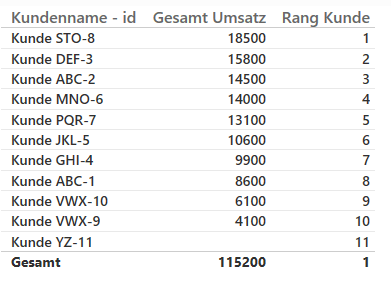
Nun fällt auf, dass die Kunden doppelt enthalten sind, z.B. Kunde „ABC“ ist zweimal enthalten. Was in diesem Fall auch korrekt ist, da es sich um zwei unterschiedliche Kunden handelt, bei denen nur das Feld Kundenname gleich ist. Wer nicht zwei Spalten benutzten möchte, kann eine neu abgeleitete Spalte im Modell erzeugen, welche [id_Kunde] und [Kundenname] kombiniert, diese Kombination ist ebenfalls eindeutig.
Lösung für das Rangproblem über DAX
Eine andere Möglichkeit ist die DAX-Formel konkreter zu gestalten. Anstatt die gesamte Tabelle zu übergeben kann auch eine konkrete Spalte übergeben werden, z. B. die Spalte [Kundenname]:
-
Rang Kundename =RANKX(All(‘Kunde‘[Kundenname]);[Gesamt Umsatz])
Wichtig ist hierbei, dass Kunden, die denselben Namen haben, gruppiert werden. Je nach Anwendungsszenario kann dies ganz praktisch sein, z. B. wenn man ein Rang über [Konzern] erstellen möchte, da sich hier, mehrere Kunden in einem Konzern bündeln.
![Abbildung 9 - Rangordnung über [Kundenname]](/sites/default/files/styles/optimize/public/inline-images/2015_09_Abbildung-9-Rangordnung-%C3%BCber-Kundenname.png?itok=8zpzjL5Z)
Ein Nachteil dieser Methode ist, dass das Measure [Rang Kundenname] nicht mit den Spalten [Konzern] und [Ort] funktioniert, siehe Abbildung 10. Das heißt wir müssen bei dieser Formel darauf achten, dass die Spalten [Konzern] und [Ort] nicht im Kontext der Auswertung auftauchen. Wenn wir ein Ranking über Ort oder Konzern haben möchten, müssten wir dafür eigene Measures erstellen.
![Abbildung 10 - Fehlerhafte Rang mit [Kundenname]](/sites/default/files/styles/optimize/public/inline-images/2015_09_Abbildung-10-Fehlerhafte-Rang-mit-Kundenname-300x175.png?itok=DSAL2AJt)
DAX-Formel für Rang über Kundenname, Konzern und Ort
Was ist aber nun, wenn man dem Nutzer nicht zumuten möchte für jedes Attribut ([Kundenname], [Konzern], [Ort]) das passende Measure auszuwählen ? Dann muss man sich mit DAX behelfen! Die Funktion ISFILTERED() gibt den Wert „true“ zurück wenn eine Spalte im derzeitigen Kontext vorkommt. Der Begriff Kontext ist in DAX sehr vielseitig, gemeint ist hier, dass die ausgewählte Spalte nicht in einem Seitenfilter, einem visuellen Filter, einem Kreuzfilter oder im Zeilenkontext vorkommt. Wer sich etwas genauer mit dem Thema Kontext in DAX beschäftigen möchte dem seien diese beiden Blogbeträge ans Herz gelegt Link 1 , Link 2 . Den Kontext können wir hier benutzten, denn sobald in einem Bericht eine Spalte enthalten ist, gibt ISFILTERED() „true“ zurück, siehe Abbildung 11.
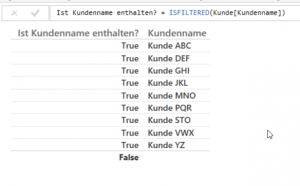
Aus dieser Eigenschaft lässt sich ein Measure erstellen, dass immer den passenden Rang je nach Attribut anzeigt und wenn mehr als ein Rang-Attribut enthalten ist, keine Werte anzeigt. Um die Formel zu vereinfachen habe ich im Voraus zwei eigene Rang-Measures für [Ort] und [Konzern] (siehe Kunde) erstellt.
-
Rang (Kundenname,Ort,Konzern)
-
= SWITCH (
-
IF ( ISFILTERED ( Kunde[Kundenname] ); „1“; „0“ )
-
& IF ( ISFILTERED ( Kunde[Ort] ); „1“; „0“ )
-
& IF ( ISFILTERED ( Kunde[Konzern] ); „1“; „0“ );
-
„100“; [Rang Kunde];
-
„010“; [Rang Ort];
-
„001“; [Rang Konzern];
-
BLANK ()
-
)
Der Trick ist hierbei, dass man alle Kombinationsmöglichkeiten der drei Attribute als Binärenzahl ausdrücken kann. Gültig sind nur die Ausdrücke die nur eine 1 enthalten. Im ersten teil der SWITCH-Abfrage wird eine Binärzahl aufgebaut, im zweiten Teil der SWITCH-Abfrage müssen dann nur die gültigen Kombinationen (100,010,001) überprüft werden. die Anzahl der Attributspalten mit
-
ISFILTERED() = „True“
gezählt werden. Die Berechnung des Ranges wird nur dann ausgeführt, wenn die Gesamtanzahl gleich 1 ist, ansonsten wird 0 angezeigt.

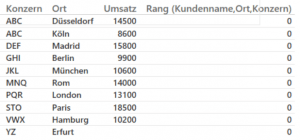
Schwächen des vorgestellten DAX-Formel
Sobald zwei Attributspalten unter einem Kontextfilter (Seiten, visuell, Kreuz) stehen, funktioniert die Formel nicht mehr, da ISFILTERD, dann zweimal „true“ zurückgibt. Eine Möglichkeit nur den Zeilenkontext abzufragen, ist mir in DAX nicht bekannt.
Fazit
In diesem Beitrag wurde erläutert wie Ränge mithilfe der RANKX-Funktion in DAX vergeben werden können. Es wurden dabei verschiedene Lösungsansätze für das Problem der nicht eindeutigen Spalten vorgestellt. Im zweiten Teil dieses Blogbeitrags werden einige kosmetische Erweiterungen vorgenommen, wie z.B. das Ausblenden von Datensätzen ohne Inhalt, und das Erstellen eines statischen Rangs.




Kommentare (0)