Die Web-Oberfläche von Azure Databricks kann einem Entwickler schon mal den letzten Nerv rauben. Bereits seit langem warte ich drauf, in meiner Lieblings-IDE (Visual Studio Code) programmieren zu können. Mit dem Release von Databricks Connect wurde mein Wunsch endlich wahr! Endlich können wir unsere Lösungen in jeder beliebigen Entwicklungsumgebung coden und dennoch live mit dem Azure-Databricks-Cluster verbunden sein.
Die Installation von Databricks Connect hat mich allerdings drei Nachmittage voller Trial & Error gekostet. Um dir diese Odyssee zu ersparen, zeige ich Ihnen die 5 Schritte, mit denen Sie ohne Umwege ans Ziel kommen.
Voraussetzungen
Ich gehe davon aus, dass Sie bereits ein Cluster in Azure Databricks angelegt haben. Da wir eine virtuelle Python-Umgebung brauchen, solltest du Anaconda installiert haben.
Auch wenn jede mit Anaconda funktionierende IDE möglich ist, orientiert sich diese Anleitung an Visual Studio Code. Hier benötigst du die Python-Extension.
Sie dürfen keine Spark-Installationen auf Ihrem PC installiert haben. Falls Sie Python schon nutzen, lohnt sich folgender Befehl:
-
pip uninstall pyspark
Schritt 1: Konfigurieren Sie Ihr Cluster
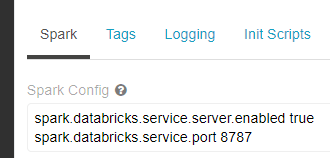
In den Advanced Options Ihres Clusters finden Sie die Spark-Config. Hier hinterlegen Sie die folgenden beiden Zeilen:
Schritt 2: Sammeln Sie die notwendigen Informationen
Tragen Sie die Infos zusammen, die wir in Schritt 3 für die Einrichtung benötigen.
- Der Host. Dieser bildet den Beginn der Databricks-URL, z. B. https://westeurope.azuredatabricks.net
- Die Organization ID. Auch diese bekommen Sie aus der URL. Es ist die Zahlenfolge, die hinter „o=“ zu finden ist, z. B. 5684337135249119
- Die Cluster ID. Im Cluster unter Advanced Options -> Tags steht die Cluster ID, z. B. 0123-062140-tines951
- Den Token. Diesen müssen Sie in Databricks generieren. Dazu gibt es auf der Website eine Anleitung. (Vorsicht: Groß- und Kleinschreibung ist wichtig!)
- Den Port. Bei Azure ist dieser immer 8787
Schritt 3: Erstellen Sie ein Virtual Environment und richten Sie Databricks Connect ein
Zunächst brauchen wir eine virtuelle Python-Umgebung. Diese muss zwingend dieselbe Python-Version wie das Cluster haben. Stand Oktober 2019 ist dies meistens Python 3.5.
Öffne die Anaconda Prompt:

Erstellen Sie eine virtuelle Umgebung:
-
conda create –name bricksEnv python=3.5

Aktivieren Sie die Umgebung:
-
conda activate bricksEnv
Installieren Sie Databricks Connect:
Wichtig: Die Version von Databricks Connect (z. B. 5.5.) muss der Version Ihres Clusters entsprechen!
-
pip install databricks-connect==5.5.*
Richten Sie Databricks Connect mit den Informationen aus Schritt 2 ein:
-
Databricks-connect configure
Teste die Verbindung
-
Databricks-connect test
Nun sollten Sie folgende Fehlermeldung erhalten. Diese beheben wir in Schritt 4.

Schritt 4: Java 8 installieren
Databricks Connect funktioniert nur mit Java 8. Laden Sie also die Java 8-Runtime von der Oracle Website. (Registrierung ist erforderlich)
Wichtig: Installieren Sie Java nicht im Standard-Pfad, sondern unter C:\Java

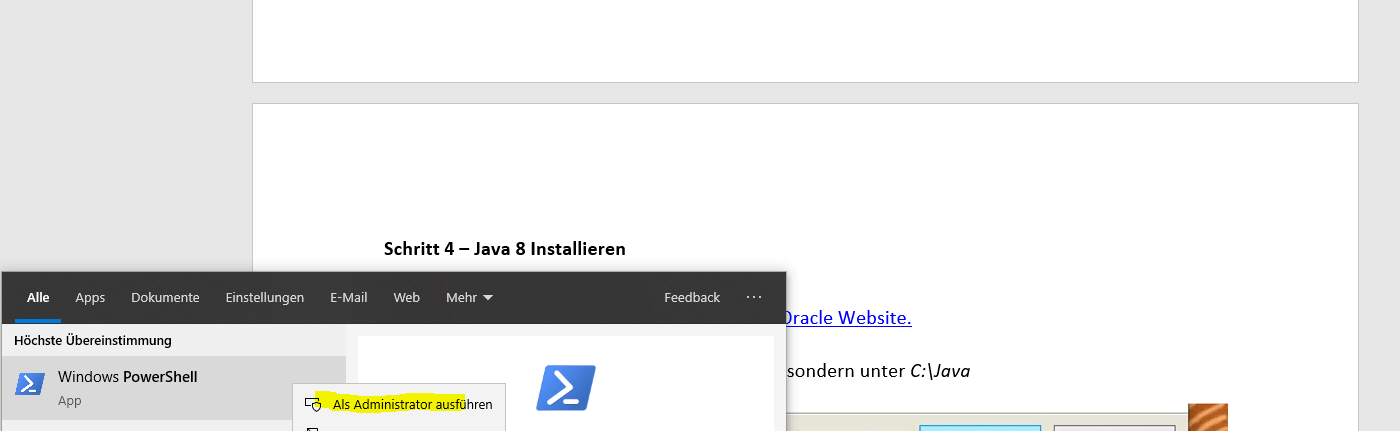
Starten Sie nun Powershell als Administrator.
Nun führen Sie folgenden Befehl aus:
-
[Environment]::SetEnvironmentVariable(„JAVA_HOME“, „C:\Java“, „Machine“)
Starten Sie nun die Anaconda Prompt neu (sonst wird die neue Umgebungsvariable nicht erkannt) und führen Sie
-
databricks-connect test
erneut aus. Die Java-Version macht nun keine Probleme mehr.

Stattdessen tritt ein neuer Fehler auf:

Diesen beheben wir in Schritt 5.
Schritt 5: Winutils installieren
Starten Sie Powershell wieder als Administrator und führen Sie folgende zwei Befehle aus:
-
New-Item -Path „C:\Hadoop\Bin“ -ItemType Directory -Force
-
[Environment]::SetEnvironmentVariable(„HADOOP_HOME“, „C:\Hadoop“, „Machine“)
Laden Sie nun die Winutils-Exce von Github herunter.

Legen Sie die Datei nach dem Download in den Ordner „C:\Hadoop\Bin\“.
Starten Sie anschließend die Anaconda Prompt neu und führe.
-
databricks-connect test
aus. Diesmal sollte der Test erfolgreich durchlaufen.
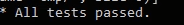
Geschafft!
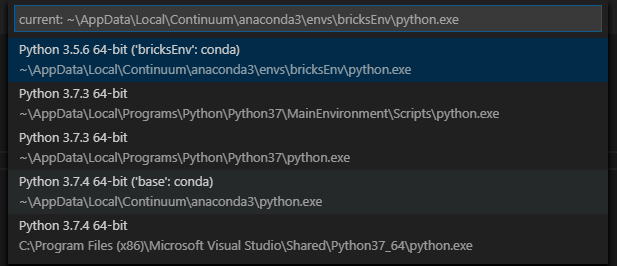
Jetzt können Sie Python-Befehle von Visual Studio aus gegen Ihr Databricks Cluster abfeuern. Achten Sie aber darauf, dass Sie im richtigen Environment sind:
Am Anfang jedes Python Files müssen Sie die Spark Session einfangen. Wie das geht, sehen Sie in folgendem Beispielcode:
-
from pyspark.sql import SparkSession
-
spark = SparkSession.builder.getOrCreate()
-
diamonds = spark.read.csv(„/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv“, header=“true“, inferSchema=“true“)
-
diamonds.show()
Das Ergebnis sieht etwa so aus:
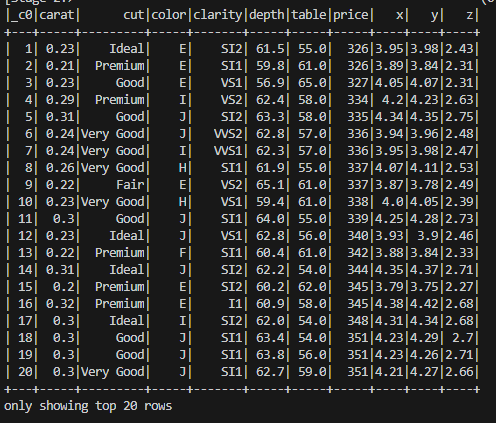
Ich hoffe, ich konnte Ihnen mit diesem Tutorial weiterhelfen. Falls Sie noch Fragen haben, schreiben Sie gerne einen Kommentar. Eine genauere Erklärung finden sie zudem in meinem Video:





Kommentare (0)