Microsoft’s Analytics Platform System (APS) offers built in transparent access to Hadoop data sources through the Polybase technology. This includes bidirectional access not only to Hadoop but also to Cloud services. The SMP SQL Server currently doesn’t contain Polybase, so access to Hadoop needs to be handled differently. Will Polybase be available in an upcoming SMP SQL Server? From the past we saw some technology making its way from PDW to SMP SQL Server, for example the clustered columnstore index, the cardinality estimation or the batch mode table operations. So let’s hope that Polybase makes it into the SMP SQL Server soon. Until then, one option is to use the HortonWorks ODBC driver and linked tables. To be honest, Polybase is a much more powerful technology since it uses cost-based cross platform query optimization which includes the ability to push down tasks to the Hadoop cluster when it makes sense. Also, Polybase doesn’t rely on Hive but access the files directly in parallel, thus giving a great performance. Linked tables are less powerful but may still be useful for some cases.
So, here we go. First, you need to download the ODBC driver from the Hortonworks add-ons page: http://hortonworks.com/hdp/addons/ .
Make sure you pick the right version (32 bit/64 bit) for your operating system. After the installation completes, we need to set up an ODBC connection. Therefore, start the ODBC Datasource Adminstrator (Windows+S, then type ‘ODBC’). Again, make sure to start the correct version (32 bit/64 bit). The installer has already created a connection but you still need to supply the connection properties. I created a new connection instead:
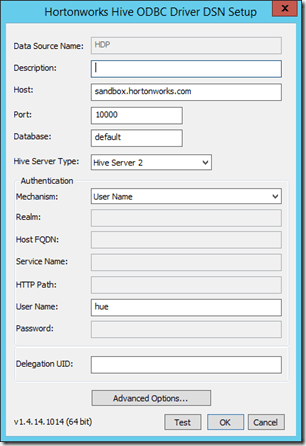
I’m connecting to the Hortonworks Sandbox here (HDP 2.1, I had problems connecting to HDP 2.2 with the current version of the ODBC driver). Instead of the host name you can also enter the IP address (usually 127.0.0.1 for the sandbox) but in order to get other tools running (like Redgate Hdfs Explorer) I configured the sandbox virtual machine to run on a bridged network and put the bridge network IP address of the sandbox (console command “ip addr”) in my local host file.
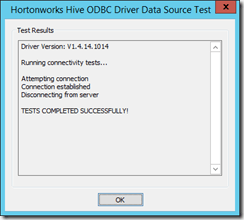
You should now click on Test to verify that the connection actually works:
In SQL Server Management Studio we can now create a linked server connection to the Hadoop system using the following command:
-
EXEC master.dbo.sp_addlinkedserver
-
@server = N’Hadoop‘,
-
@srvproduct=N’HIVE‘,
-
@provider=N’MSDASQL‘,
-
@datasrc=N’HDP‘,
-
@provstr=N’Provider=MSDASQL.1;Persist Security Info=True;User ID=hue;‘
Depending on you Hadoop’s security settings, you might need to provide a password for the provider string as well. The @server name is used to refer to the linked server later while the @datasrc names the ODBC connection (see “Data Source Name” in the configuration dialog of the connection above).
With the new linked server, we can now explore the Hive database in Management Studio:
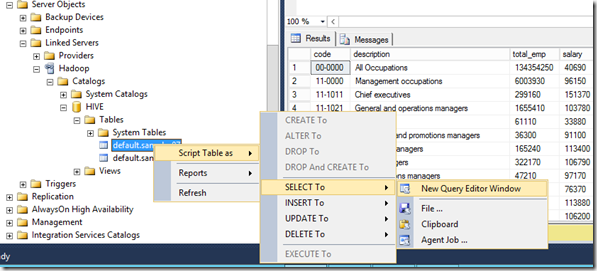
In order to run a query on for example table “sample_07” you can user one of the following commands:
-
select * from openquery (Hadoop, ’select * from Sample_07′)
or
-
select * from [Hadoop].[HIVE].[default].[sample_07]
For both queries, “Hadoop” refers to the name of the linked server (@server parameter in the SQL statement from above).
If you get the following error message, this means that you are not allowed to query the table:
-
OLE DB provider „MSDASQL“ for linked server „Hadoop“ returned message „[Hortonworks][HiveODBC] (35) Error from Hive: error code: ‚40000‘ error message: ‚Error while compiling statement: FAILED: HiveAccessControlException Permission denied. Principal [name=hue, type=USER] does not have following privileges on Object [type=TABLE_OR_VIEW, name=default.sample_07] : [SELECT]‘.„.
-
Msg 7306, Level 16, State 2, Line 1
-
Cannot open the table „“HIVE“.„default“.„sample_08″“ from OLE DB provider „MSDASQL“ for linked server „Hadoop“.
In this case, you should simply give the user from you ODBC connection the SELECT right. To do so, run the following query in Hive:
-
grant select on sample_07 to user hue;
That’s it. You should now get the contents of the table in SQL Server:
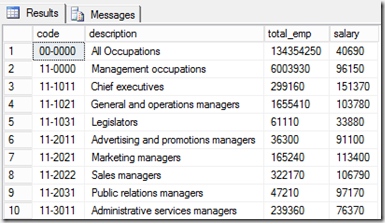
You might want to set the length of string columns manually because Hive does not return the size of the string column (in Hive, the column type is simply “string”). The size returned from the query results from the advanced ODBC-settings of our connection. I left everything on default here, so here is how it looks:
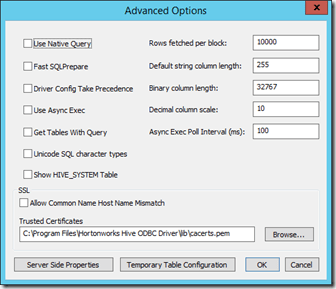
So, the default string column length is 255 here. Let’ check and copy the data over to SQL Server:
-
select * into sample_07 from [Hadoop].[HIVE].[default].[sample_07]
The resulting table looks like this:
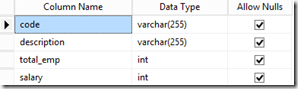
To have a more precise control of the column length, you should use the convert function here, for example:
-
select
-
convert(nvarchar(50),[code]) [code],
-
convert(nvarchar(80),[description]) [description],
-
total_emp,
-
salary
-
from [Hadoop].[HIVE].[default].[sample_07]
Be careful with the remaining setting in the advanced options dialog. For example, checking “Use native query” means that you pass the query (openquery-Syntax) as it is to Hive. This could be intended to fully leverage specific features of Hive, but this could also lead to errors if you’re not familiar with the HiveQL query syntax. Also, to get a better with larger tables you might want to adjust the “Rows fetched per block” option to a larger value.
With HDP 2.2 you should also be able to write to the table (create a new table, grant all permissions and run an insert into) but I couldn’t do on my HDP 2.1 machine.
Summary
Until Polybase makes it into the SMP SQL Server product, Hadoop data may be queried from SQL Server using the ODBC driver and the linked server object. This could also be an option for Analysis Services to connect to Hadoop by using SQL Server views via linked server, since Analysis Services doesn’t support ODBC in multi dimensional mode. However, Polybase on the APS gives a much better performance because of the intelligent cross platform query optimizer and Polybase can also be used to write data to Hadoop, so I hope we’ll find this technology in the SMP SQL Server soon.





Kommentare (0)