SQL Server 2005 | SQL Server 2008 | SQL Server 2008R2
This post is about a problem I faced some years ago. The source system was SAP with user defined hierarchies, in this case within the cost center and cost type tables. Parallel hierarchies are well supported in SQL Server BI but in this case, users in SAP could define multiple hierarchies on their own and they wanted these hierarchies to be also available in the OLAP cube. For example, costs associated with the cost center 1000 should be analyzed as shown below:
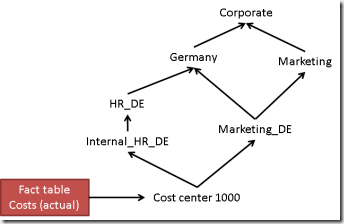
All costs that are booked on cost center 1000 have to appear in the hierarchy as shown in the sketch. And end-users may also be able to create new hierarchies (for example to analyze a certain project). Of course there may be better ways to model this but in this case we had basically two tables for the cost centers:
- table CC (Cost Center)
- table CCG (Cost Center Group)
Table CC contains all cost centers (for example the above cost center 1000) together with additional information (like name, responsible person etc.) while table CCG contains the hierarchy. in CCG we basically find two columns:
- Node name
- Parent node name
| Node | Parent Node |
| 1000 | Internal_HR_DE |
| Internal_HR_DE | HR_DE |
| HR_DE | Germany |
| 1000 | Marketing_DE |
| Marketing_DE | Germany |
| Germany | Corporate |
| Marketing_DE | Marketing |
| Marketing | Corporate |
Facts (in this case actual or planned costs) are associated with the cost center number (for example 1000). Usually, parent-child hierarchies may be used in this case where we have a very dynamic structure and we do not know the number of levels. However, parent-child may only be used if each node has at most one parent. But here we find the cost center 1000 having two parents (Internal HR Costs DE and Marketing_DE). The same situation exists with the Marketing_DE node (having parents Marketing and Germany).
The solution I’m presenting here is to create additional nodes until each node only has one parent. This is possible as each node of a parent-child hierarchy in SSAS has a name and a key property. So, the name will be identical, while the key will be different. In order to show the process, let’s add internal keys to each of the hierarchy elements.
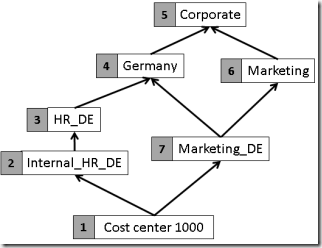
What we have to do now is to create additional nodes for every node that has more than one parent. Let’s start with the ‘Marketing_DE’ node:
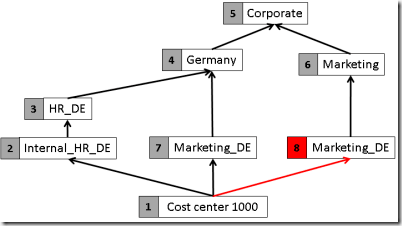
The additional node gets a new (internal) key, in this example the number 8. But there is still a node with multiple parents: the cost center 1000. Let’s also transform this into separate nodes:
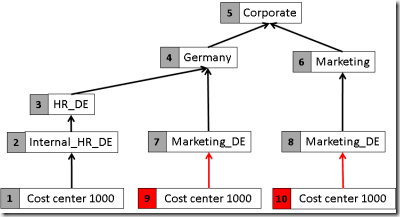
After this step, each node has at most one parent and therefore the structure can be modeled as an SSAS parent-child hierarchy.
But now, we have to think about the fact rows. Without the hierarchy, facts would have been associated to the cost center by using the internal key (surrogate key), so for example 1000 € that are booked on cost center 1000 would appear in the fact table like
| DateKey | CostCenterKey | … | Amount |
| … | … | … | … |
| 20110630 | 1 | … | 1000 |
| … | … | … | … |
But now, we have to associate this single fact row to three rows in the dimension table (as the cost center 1000 appears three times now). Therefore we have to use a many-to-many approach, so we add another table, a so called bridge table with the following rows:
| CostCenterKey | CostCenterDimKey |
| … | … |
| 1 | 1 |
| 1 | 9 |
| 1 | 10 |
| … | … |
For technical reasons, our fact table has to be linked to a dimension (of flat cost centers), which is also used by the bridge table. This is shown in the following image:
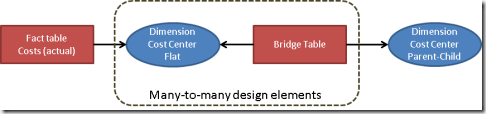
The most difficult part here is to “normalize” the parent-child structure. One way to do this is to use a stored procedure. Here is the code I used. Within this procedure, the following tables are used:
| masterdata.Costcenter | the flat table of cost centers (only leaf-level). The key field is the cost center number (for example 1000 for our cost center from above) | ||||||
| masterdata.CostcenterGroup | the hierarchy structure as shown above | ||||||
| ods.CostcenterGroupExpanded | Output table: the expanded tree containing the fields of the table masterdata.Costcenter plus the following additional fields:
|
Here is the code:
-
CREATE PROCEDURE [dbo].[ExpandCostcenterGroup]
-
AS
-
SET NOCOUNT ON
-
truncate table ods.costcenterGroupExpanded
-
declare @level int
-
declare @affectedrows int
-
declare @totalrowcount int
-
set @level=0
-
insert into ods.costcenterGroupExpanded(costcentergroup,Parentgroup,Description1,Description2,Responsibility,AccountingArea)
-
Select distinct costcenterGroup, Parent,Description1,Description2,Responsibility,AccountingArea from masterdata.costcentergroup
-
— Initialize all keys
-
update ods.costcenterGroupExpanded
-
set ParentKey=(select min(costcenterkey) from ods.costcenterGroupExpanded where costcenterGroup=c.Parentgroup)
-
from ods.costcenterGroupExpanded as c
-
where not c.ParentGroup is null
-
set @affectedrows=1
-
while @affectedrows>0
-
begin
-
Set @level=@level+1
-
set @totalrowcount=(select Count(*) from ods.costcenterGroupExpanded)
-
insert into ods.costcenterGroupExpanded(costcentergroup,Parentgroup,ParentKey,„level“,Description1,Description2,Responsibility,AccountingArea)
-
select distinct cparent.costcentergroup, cparent.Parentgroup,cparent.costcenterKey,@level,cparent.Description1,cparent.Description2,cparent.Responsibility,cparent.AccountingArea
-
from ods.costcenterGroupExpanded as cparent inner join ods.costcenterGroupExpanded as cchild on
-
cparent.Parentgroup=cchild.costcenterGroup
-
where cparent.ParentKey!=cchild.costcenterKey
-
and cchild.„Level“=@level–1
-
set @affectedrows=@@rowcount
-
end
-
return
-
GO
To keep things simple, I truncate the output table CostcenterGroupExpanded here. However, there is a drawback with this approach: The surrogate keys may change after changes of the imported source tables. This will result in a problem for example for the Excel users. If you’re using filters like ‘show this element only’, only the key is stored.
In order to avoid this you will need to store the mapping and the assigned surrogate key separately. Here it is necessary not only to store the combination of cost center/parent cost center/surrogate key but the whole branch up to the root instead. If you look at the example above you will find two entries of ‘Cost Center 1000’ –> ‘Marketing_DE’, so this is not unique. You have to store the full path up to the root for each node (not only for the leaf-nodes) to make it unique:
| Path | Given Surrogate Key |
| 1000 –> Internal_HR_DE –> HR_DE –> Germany –> Corporate | 1 |
| 1000 –> Marketing_DE –> Germany –> Corporate | 9 |
| 1000 –> Marketing_DE –> Marketing –> Corporate | 10 |
| Marketing_DE –> Germany –> Corporate | 7 |
| Marketing_DE –> Marketing –> Corporate | 8 |
| … |
In order to store the full path up to the root level I recommend using a hash code (MD5 for example) as this is easier to handle as a long list of node names. In this case our additional key store table would look like this
| PathMD5 | Given Surrogate Key |
| 417913d10ef49f5ff90db9db9f3d2569 | 1 |
| 8e27be6b156a52016e01dc049bc39126 | 9 |
| 52b1bcaec016e09d4086f37e63814aa5 | 10 |
| … |
The sample code above does not manage this key store table so the keys may change a lot on each load. But for practical purposes you will have to add this key management to make sure the same node always gets the same key.





Kommentare (0)