PDW 2012
As promised in my previous post about ROLAP on PDW, here are some more tips, tricks and recommendation for using SSAS in ROLAP mode on a PDW source. Please read part 1 first as most of the tips from that post are not being repeated here.
Keep your statistics up to date
Ok, this was also in my last post but it cannot be said often enough. So here it is again. Statistics are most important when it gets to query performance. Make sure you have statistics at least on all columns that participate in join, filtering (where-clause) or aggregation (group by-clause) operations.
Clustered Columnstore Index
As I already mentioned, the clustered column store index (CCI) is the key to running SSAS in ROLAP mode on the PDW as it gives a very good performance. In fact, all big tables in our data warehouse on PDW are currently in CCI storage. CCI stores the data natively in column store compressed format thus being able to achieve the outstanding performance. However, it’s important to understand how the CCI works. In short, when data is written to the CCI, it is first written to a row store table internally. This is called the delta store and the data is stored there as a row group. From that delta store, the data is compressed either synchronously (when larger batches hit the CCI table) or asynchronously (when smaller batches are inserted causing the current row group to reach its storing limit) using the tuple mover process. And since the delta store exists for each distribution and each partition, a lot of rows of the CCI table may actually be in row store mode either waiting to be compressed (row group in status ‘CLOSED’: waiting for tuple mover) or waiting for more rows to arrive (row group in status ‘OPEN’). Imagine a two compute node appliance with 100 partitions, giving 2×8=16 distributions and therefore potentially 1600 open delta stores. Each of those may potentially contain uncompressed rows. And there may be many more row groups in status ‘CLOSED’ also containing uncompressed rows.
The more rows are in uncompressed state, the slower the queries get accessing the data. Therefore it is very important to carefully monitor the state of your CCI tables for uncompressed rows. You can find a very useful query for that in the meta data section of the help file:
-
— show rowgroups and status of a table by partition
-
SELECT IndexMap.object_id,
-
object_name(IndexMap.object_id) AS LogicalTableName,
-
i.name AS LogicalIndexName, IndexMap.index_id, NI.type_desc,
-
IndexMap.physical_name AS PhyIndexNameFromIMap,
-
CSRowGroups.*,
-
100*(total_rows – ISNULL(deleted_rows,0))/total_rows AS PercentFull
-
FROM sys.objects AS o
-
JOIN sys.indexes AS i
-
ON o.object_id = i.object_id
-
JOIN sys.pdw_index_mappings AS IndexMap
-
ON i.object_id = IndexMap.object_id
-
AND i.index_id = IndexMap.index_id
-
JOIN sys.pdw_nodes_indexes AS NI
-
ON IndexMap.physical_name = NI.name
-
AND IndexMap.index_id = NI.index_id
-
JOIN sys.pdw_nodes_column_store_row_groups AS CSRowGroups
-
ON CSRowGroups.object_id = NI.object_id
-
AND CSRowGroups.pdw_node_id = NI.pdw_node_id
-
AND CSRowGroups.index_id = NI.index_id
-
WHERE o.name = ‚<insert table_name here>‘
-
ORDER BY object_name(i.object_id), i.name, IndexMap.physical_name, pdw_node_id;
In general, if a lot of rows are in row groups with status ‘OPEN’ or ‘CLOSED’ you should take action:
Row groups in status ‘CLOSED’: The tuple mover process should compress these row groups (new status ‘COMPRESSED’) in the background. However, if there are a lot of row groups in status ‘CLOSED’ the tuple may be behind. In order to help the tuple mover process you should run an alter index … reorganize to compress these row groups. Usually this works pretty fast and the table remains online for queries.
Row groups in status ‘OPEN’: If you find many rows in row groups of status ‘OPEN’ you may consider reducing the number of partitions in your table (if possible) or compress these row groups manually using an alter index … rebuild. However, the rebuild takes some time and needs an exclusive lock on the table. So, if your workload is designed to use partition switching you may want to perform the index rebuild on the source partition before switching it into the final table.
Either way, you should carefully monitor your CCI tables for the ratio of uncompressed row groups in order to have a good query performance, especially for ROLAP queries.
Dimensions in MOLAP or ROLAP?
Now that we’re having the fact tables in ROLAP, what about the dimensions? Wouldn’t it be nice to have them in ROLAP too? From what we experienced in practical use, you should have all your dimensions in classical MOLAP mode. Only if you have a very large dimension, which is difficult to process, I would go for ROLAP. The main reasons are:
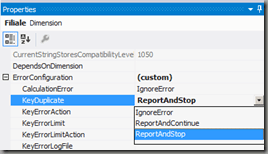
First Reason: ROLAP dimensions may give false positives of the duplicate key error at query time. This effect is discussed here and can also be found on technet here (search for “false positives”). However, the solution proposed on technet was to switch error configuration to ignore error:
“For a ROLAP dimension, you should disable DuplicateKey errors. This error was enabled by default in AS 2008 to try to help users catch incorrectly defined attribute relationships — but if you are using ByTable processing or ROLAP storage, then it will only give you false positives.”
I don’t think that this is a safe and good approach (see my post here on this topic), so by having the dimensions in MOLAP mode with activated key duplicate error detection, I’m sure the keys are consistent.
Second Reason: From my observation, SSAS generates less and better queries if the dimension is in MOLAP mode (the query still goes to the underlying table using SQL). If the dimension is in ROLAP mode, SSAS fires one additional queries to the dimension table before going to the fact tables. For MOLAP dimensions we see just one queries joining the fact table to the dimension tables.
Which resource class should I use?
Higher resource classes on the PDW (more query slots) usually improve the query performance of high workload queries at the price that less queries can be run in parallel. But for ROLAP we want many users to execute rather simple queries in parallel. What makes things worse is that some ROLAP operations are solved using multiple queries for only one pivot table. Therefore we made the best practical experience using smallrc (default) resource class for the SSAS queries.
Take care with non-aggregatable data types
For a MOLAP cube it’s fine to have a measure of type datetime (hidden, just for drill through) and set the aggregation function to ‘none’. But for ROLAP the SSAS engine still tries to fetch a sum for those measures causing the query to fail because sum aggregate is not supported for datetime. One solution is to use aggregation functions min or max for these cases.
Also, you should take care with measures of type integer. Even if you’re only using those measures as a flag on an intermediate bridge table, the SQL query may result in an integer overflow error.
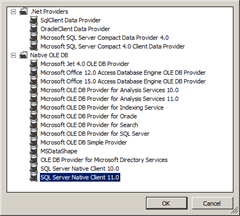
Use SNAC as data base driver
As described before, PDW should be addressed through the simple SNAC driver (SQL Server Native Client) as shown in the screenshot below:
Miscellaneous
If you get the error “42000, Parse error at line: 1, column: 51: Incorrect syntax near @ResultCode”, you probable have proactive caching set to on which isn’t supported on the PDW yet.
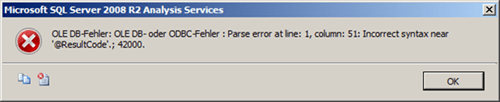
The reason for the error is, that for proactive caching, SSAS tries to execute the stored function sp_trace_create on the data source:
-
DECLARE @ResultCode INT;
-
DECLARE @TraceId INT;
-
EXEC @ResultCode = sp_trace_create @TraceId OUTPUT, 1;
-
SELECT @ResultCode as ResultCode, @TraceId as TraceId;





Kommentare (0)