Power Query is a great and flexible tool for getting and transforming data from different sources into Excel or Power Pivot. The standard procedure for Power Query is to read a full table and to replace the destination with the result of the current query. This is exactly what we need for most use cases of Power Query. However, if you like to add new data to existing data you can still use Power Query but you have to follow a slightly different approach.
For example, let’s say we want to create a list of the blog posts while the RSS feed only delivers the most recent posts. In this case we would need to add the the query results to the existing data.
Let’s start with my olap blog. The RSS feed delivers only the last 25 entries of my blog. In order to load this with Power Query, I’m using the load from web function:
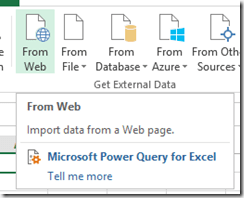
The dialog asks for the URL (I’m using my blog’s mirror here at http://ms-olap.blogspot.com/feeds/posts/default)
If Power Query does not automatically detect this as an XML table you can insert the XML.Tables(…) function as shown below:

The items are stored in the last column (entry table) which can be expanded by clicking on  button right between “entry”. For my example I’m only interested in the publication data and the title.
button right between “entry”. For my example I’m only interested in the publication data and the title.
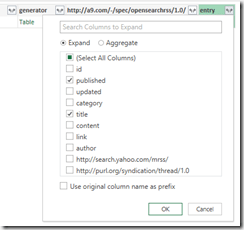
By expanding this table we get one row per blog post. In order the get the title, I’m expanding the last column (in my case title.1 since there is already a column title for the title of the blog) to its text value:
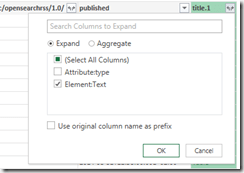
Finally, I changed the type of the first column to DateTime and I renamed the columns as shown below:

The full script generated by Power Query so far looks like this:
-
let
-
Source = Xml.Tables(Web.Contents(„
-
http://ms-olap.blogspot.com/feeds/posts/default“))
-
,
-
#“Expand entry“ = Table.ExpandTableColumn(Source, „entry“, {„published“, „title“}, {„published“, „title.1“}),
-
#“Expand title.1″ = Table.ExpandTableColumn(#“Expand entry“, „title.1“, {„Element:Text“}, {„Element:Text“}),
-
#“Removed Columns“ = Table.RemoveColumns(#“Expand title.1″,{„id“, „updated“, „category“, „title“, „subtitle“, „link“, „author“, „generator“, „
-
http://a9.com/-/spec/opensearchrss/1.0/“})
-
,
-
#“Split Column by Position“ = Table.SplitColumn(#“Removed Columns“,“published“,Splitter.SplitTextByPositions({0, 19}, false),{„published.1“, „published.2“}),
-
#“Changed Type“ = Table.TransformColumnTypes(#“Split Column by Position“,{{„published.1“, type datetime}, {„published.2“, type text}}),
-
#“Removed Columns1″ = Table.RemoveColumns(#“Changed Type“,{„published.2“}),
-
#“Renamed Columns“ = Table.RenameColumns(#“Removed Columns1″,{{„published.1“, „Date“}, {„Element:Text“, „Title“}})
-
in
-
#“Renamed Columns“
We can now load this result to the Workbook by clicking the “Close & Load” button. Now, here comes the interesting part. Up till now, the RSS feed only delivers the last 25 rows, so whenever there is a new post, the oldest post would be removed from the table. Let’s say we’d like to add new posts to the table.
To do so, I’m creating a new query named “Existing data” from the data we just loaded into the workbook:
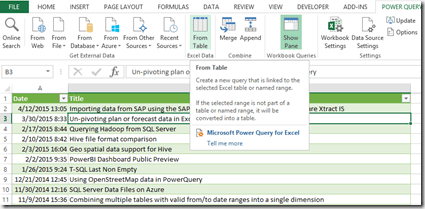
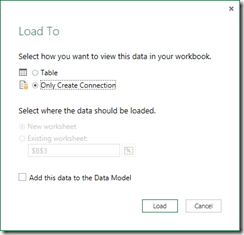
Using the “Save & Load To …” function in the ribbon, we can choose to only create a connection (no data is actually moved here):
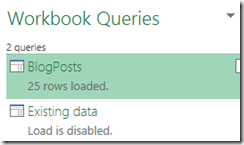
The workbook queries pane now looks like this:
We can now edit the first query (“BlogPosts”) again. In the home tab of the Power Query ribbon you can find the options for combining queries.
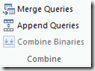
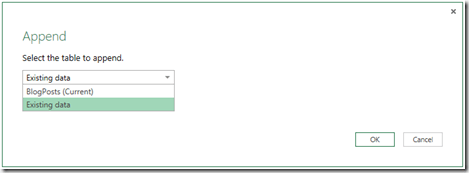
In my case, I simple decide to append the new data to the existing one. If you have a key to match the same rows, you could also do a merge based on the key column (for example if there are updated rows).
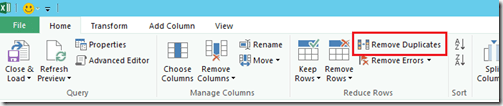
The result is that we now have 25 rows from the existing table plus 25 rows recently read from the blog. At this point of time, the entries are identical so we have 25 duplicates. I remove the duplicated rows here using the “Remove duplicates” function.
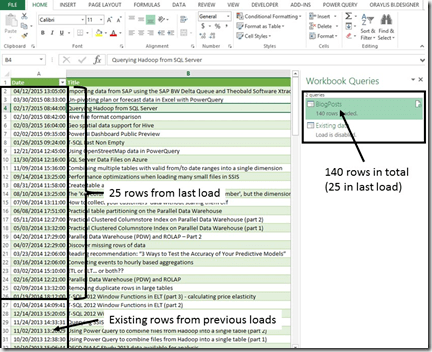
We can now save & load the query again. In order to demonstrate the effect, I’m pasting the remaining blog posts (which cannot be pulled by the RSS feed) into the Excel table:
Summary
While full loads usually are the most usefull approach for loading data with Power Query, you can also build incremental load procedures by joining or appending the new data to the existing data.





Kommentare (0)