SQL Server 2005 | SQL Server 2008
Handling different granularity (for example actual and plan values) can get a little bit complicated. Of course there are standard methods, like splitting up the less granular data in order to meet the finer granularity. Or you could use a parent-child structure as this allows you to store data at different levels in the tree-like structure. Or you could supply ‘unknown’ elements to map the less granular information.
For this post I want to show a different approach. Usually for each dimension we are linking all fact tables that refer to this dimension to the same key in the dimension table (the dimension’s primary key). However, the data source view also allows us to link facts to different key columns in the same dimension table.
In my simple scenario I have time dimension (called DimDate) and two fact tables: Order and Order Plan. The orders are on a daily basis while the order plan is on a monthly basis. We want to link both fact tables to the same time dimension as shown below:
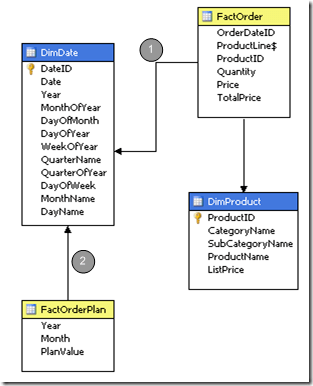
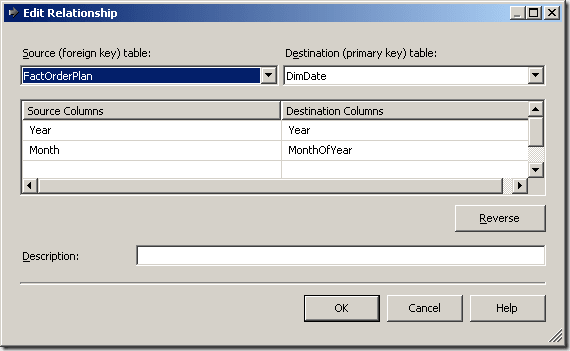
The link from the fact order table to the time dimension DimDate (marked as 1 in the sketch above) is the usual link from the fact table to the primary key of the DimDate table. The time dimension is on daily granularity and so are the order facts. But for the plan value fact table FactOrderPlan, the link to the time dimension is realized by using two key columns: Year (as the year number, eg. 2008) and month (as the month number, eg. 11 for November), so the link in the data source view looks like this:
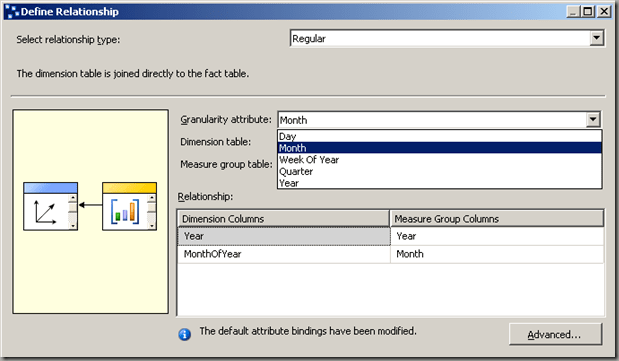
For our cube it is important to specify the right granularity attribute. While the order table is linked to the Day (granularity attribute), we link the order plan fact table to the month attribute and define the proper key mappings for that.
Now, the dimension usage looks like this:
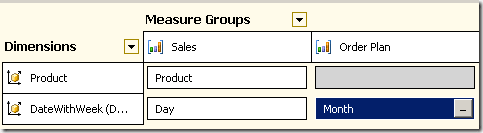
We also defined proper attribute relationship for the time dimension accordingly to build up a year->quarter->month->day hierarchy.
So let’s take the first look at the cube created by this method:
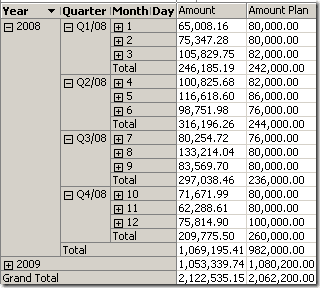
This first look is as expected. As long as we are at a common granularity level shared by both fact tables, we can see the values correctly. Also, the aggregation of both fact sources works fine (although they are at different granularity).
Now, let’s drill down to the day level which is not present in our planning data:
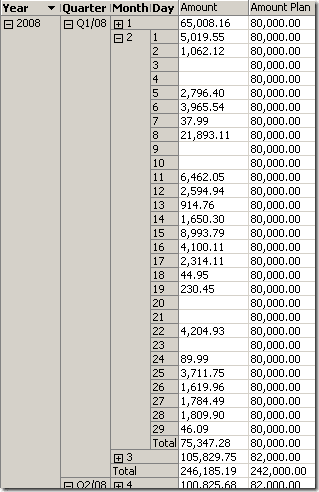
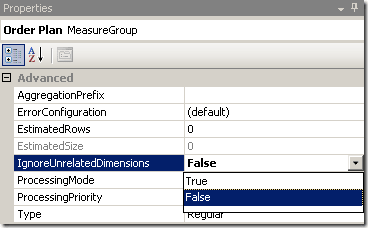
The behavior here is exactly the same as for other unrelated dimensions! The value of the nearest matching hierarchy is taken for the levels below. Sometimes this behavior of the cube confuses the users, but we can still change this behavior by changing the parameter IgnoreUnrelatedDimensions:
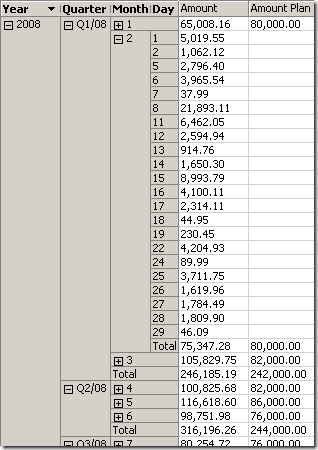
Now, the planning values below the month granularity level have disappeared:
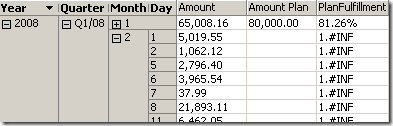
However, if you want to create a calculated measure that is also based on the planning values, you should be aware of the fact, that the values are simply not existing any more at the day level. For example, let’s define a calculated measure PlanFulFillment using the following expression:
[Measures].[Amount] / [Measures].[Amount Plan]
At the day level, the measure Amount Plan does not exist, so this results in computation errors:
You could still use the non-empty behavior for the calculate measure (set to “Amount Plan”) in order to have these computations disappear. However, if you want to refer to the monthly value, you can simple use the ValidMeasure MDX function that is always helpful in conjunction with IgnoreUnrelatedDimensions=false. So after defining our calculated measure as [Measures].[Amount] / ValidMeasure([Measures].[Amount Plan]) the result looks like this (at day level, the monthly values for the planning data is taken)
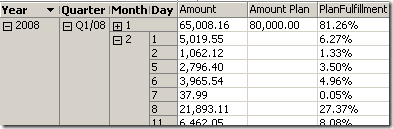
So, surprisingly enough (at least for me), everything behaves exactly like we wanted it to do and this makes the approach to an alternative in some scenarios. Again, please check your attribute relationship carefully and also spend some time on testing the result as the approach can get dangerous for more complicated attributes structures.
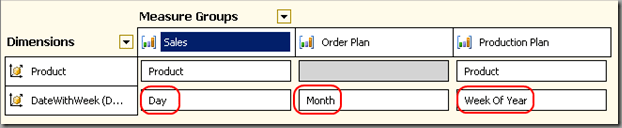
I also checked this design with more attributes and parallel hierarchies in the time dimension (for example calendar week) and more fact tables (for example production plan) and the aggregation was still correct. Having IgnoredUnrelatedDimensions set to false is helpful here to clearly see, which fact is selected at the right granularity level.
Following is an example with three fact tables (one at day level, one at month level and one at week level):




Kommentare (0)