Im 1. Teil dieser Blog-Serie bin ich allgemein auf Vereinfachungen eingegangen, die ich an BI.Quality vorgenommen habe – meinem Tool für eine laufende Prüfung der Datenqualität. Dabei hatte ich auch schon eine neue Funktion angesprochen, die im Kontext des Redesigns hinzugekommen ist: Die Verwendung von Ergebnismatrixen in den Vergleichsmessungen. Auf dieses Feature möchte ich nun näher eingehen.
Denn: Die Ergebnismatrixen ermöglichen es, ganze Abfrageergebnismengen miteinander zu vergleichen. Entsprechend lassen sich Messergebnisse bzw. Abweichungen einzelner Zellen – analog zu den übrigen Messungen – gewichten und übersichtlich darstellen. Ein typischer Anwendungsfall ist beispielsweise die Gegenüberstellung von Werten auf Tages- oder Wochenebene und den entsprechenden Werten des Vorjahres. Ebenso lassen sich Tabellen im Produktivsystem mit jenen im Abnahmesystem vergleichen.
Aufbau des Features
Die Ergebnismatrixen resultieren aus den konkreten Anforderungen in einem unserer Projekte. Die Umsetzung erfolgte in mehreren Schritten: Zunächst habe ich eine neue Ergebnistabelle erstellt, die die Messergebnisse und deren Bewertung speichert. Bewusst habe ich mich für ein transponiertes Format entschieden, da bei einer Matrix-Messung weder die Anzahl der Spalten noch deren Struktur vorgegeben ist. Diese Informationen werden letztendlich aus der Abfrage bzw. deren Ergebnis dynamisch ermittelt. Analog dazu habe ich auch die statischen Abfragen umgestaltet: Hier sind nun ebenfalls die Anzahl und Struktur der Spalten nicht mehr vorgegeben.
Wie schon bei den anderen Messungstypen, bilden parametrisierbare Abfragen, definierte Grenzwerte sowie die Gewichtung ggf. auftretender Abweichungen die Basis der Matrixvergleiche. Für die Erhebung dieser Messergebnisse und die Gewichtung der Abweichungen habe ich eines der bestehenden SSIS-Pakete erweitert.
Durchführung der Messungen
Die Messungen als solche werden mit einer C#-Skript-Komponente umgesetzt, die die Quelle des Datenflusses darstellt. Dadurch erziele ich die notwendige Flexibilität mit Blick auf variierende Spaltenzahlen und Strukturen.
Die Komponente führt zunächst die beiden zu vergleichenden Abfragen aus und speichert die Ergebnisse jeweils in ein DataTable-Objekt. Anschließend werden die beiden Objekte zellenweise verglichen, wobei die Zeilen über eine Schlüsselspalte miteinander verknüpft werden. Treten Abweichungen auf oder ist ein Wert nur in einer der beiden Ergebnismengen enthalten, so wird dies entsprechend dokumentiert. Abweichungen um „0“ werden dabei ignoriert.
Hier ein vereinfachtes Beispiel für den Vergleich der beiden Ergebnismengen:
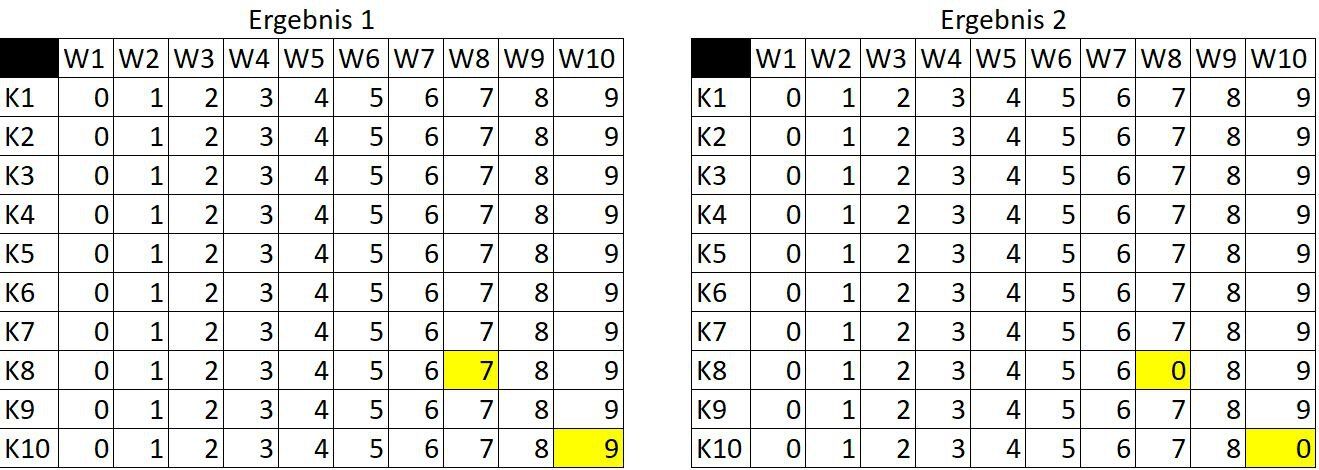 In der Quellkomponente wird das Ergebnis wie folgt dargestellt:
In der Quellkomponente wird das Ergebnis wie folgt dargestellt:

Da für den Nutzer nur die tatsächlichen Abweichungen von Interesse sind, zeigt die Quellkomponente das Ergebnis komprimiert an:
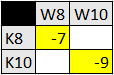
Neben der absoluten Differenz werden auch die prozentuale Differenz sowie etwaige Abweichungen von definierten Grenzwerten und deren Gewichtung ermittelt und gespeichert. Der Report stellt dann die Messergebnisse innerhalb einer Matrix dar. Zu diesem Zweck werden die Ergebnisse erneut transponiert: Für jede Zelle der Ergebnismenge gibt der Report die Differenz, Abweichung und Gewichtung aus.
Im folgenden Beispiel dient „IDCol“ als Schlüsselspalte. Die Spalte „Col1“ weist für die Schlüsselwerte 1, 2 und 3 Abweichungen auf. Die Spalte „Col2“ zeigt Abweichungen für die Schlüsselwerte 1, 4 und 5:
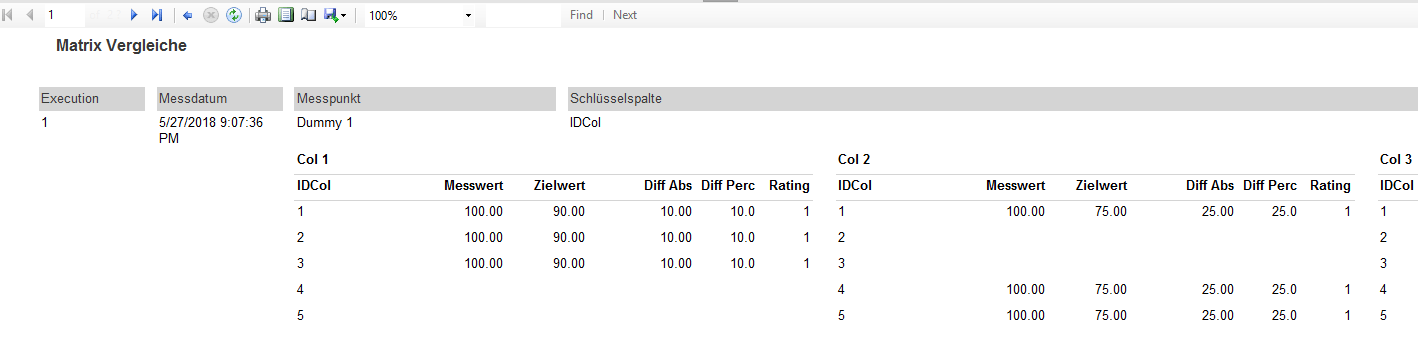
Bei dem Layout des Reports handelt es sich noch nicht um die finale Version. Allerdings wird es bereits als Prototyp in einem Projekt verwendet.
Im dritten und letzten Teil werde ich darauf eingehen, wie neben SQL Server und SSAS auch Oracle-Datenbanken angebunden werden können. Zudem zeige ich, wie sich Nutzer ereignisgesteuert über Abweichungen benachrichtigen lassen können.




Kommentare (0)