PDW v1/PDW 2012
In my last post I started with two important considerations for the distribution key:
- Skew (data being equally distributed)
- Distribution compatibility (table joins for most typical queries are supported in an optimal way)
So, here are the remaining two considerations, I’d like to present here:
Consideration 3: Aggregation compatible queries
Expected aggregations also play a role when choosing a good distribution key. There is an excellent post by Stephan Köppen about aggregation compatible queries. As ‘aggregation’ says, we’re talking queries that do a group by (like many DWH queries do). As long as the distribution key is present in the group by field list, PDW can be sure that each compute node can do the aggregation on its on (each aggregation group is on a single compute node). For example, in the following example we have a sales table that is distributed on the article and we’re running a query that groups sales by article:
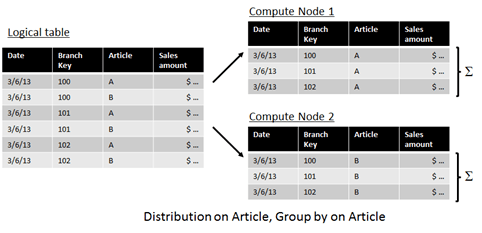
As you can see, distribution on article guarantees that all the rows for article A are getting to the same compute node. Therefore a group-by-operation on article A can be performed on this node. The same is true for article B (may be hashed to the same compute node as article A, but the point is that all rows of article B also sit on the same compute node). Please note that this is just an example. Depending on the hash function article B may be on the same node as article A but the point is that all rows for each article are on the same compute node.
Now let’s assume we’re still distributing on article but now we’re doing a group by on the branch:
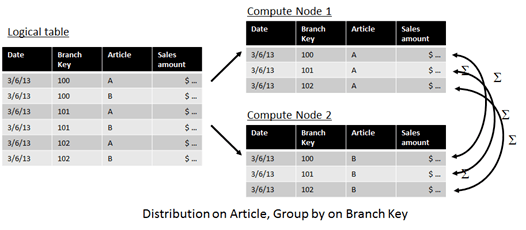
In this case, rows for the same branch (may be) spreaded over several compute nodes. Therefore it is necessary for the PDW to move data between the nodes in order to perform the group by operation.
Again, I’d like to refer the Stephan’s post regarding the way PDW handles aggregations. Even if a single node can handle the “group by” on its own it may still be necessary to “blend” the results on the compute node. For example, if we query the example above on article and branch, each node would deliver three aggregated values which then have to be put together in order to get the final result set.
So, as a conclusion we can say that a query is aggregation compatible if the distribution key is present in the group-by field list.
Consideration 4: Query behavior and typical workload
As explained in considerations 2 and 3 we have to consider the expected workload in order to find a good distribution key (and table layout, i.e. merging two tables into one, choosing replicated tables etc.). And this is also true for consideration 1. While usually we want to distribute our data „equally” on all of the compute nodes (no skew), there may be query situations that may be supported by a different distribution strategy. For example, in a call center we want the call center agent to access aggregated values for a single customer almost instantly when the customer is routed to the call center agent’s desk. In this case, the group-by will contain an identification for the customer (customer number, phone number etc.). Now if the data for this customer is distributed over multiple compute nodes, PDW has to collect this data on the control node before it can be routed back to the caller. If the data is only one compute node, this node can immediately start a so called “return operation” routing the data directly to the query client (no action needed on the control node). The difference in query time may not be that much, but imagine you have a very large call center with a lot of calls getting in each minute. So instead of few queries scanning a large amount of data, we now have lots of queries that are rather simple and only accessing a small fraction of total data. Distributing single queries on multiple machines wouldn’t give a benefit here, but distributing the query workload on multiple machines would help (much like a classical SQL Server cluster). And in this scenario we wouldn’t even care much about possible skew in the data.
So, the query behavior plays an important role when deciding for a good distribution key.
Putting it all together
When reading the considerations from above, one might think that deciding for the best distribution key seems is a very difficult process. Since it depends on the query behavior, you can’t prepare yourself for every possible query. So what shall we do?
Of course, we want to get the best possible performance out of the PDW, but keep in mind:
- Even with a “non-optimal” distribution key, PDW will still be extremely fast. Moving data between the nodes is what the PDW is designed for. So doing a shuffle move operation is not necessarily a bad thing.
- The decision for the distribution key is not a decision to last for ever. In fact you can easily redistribute the table (CTAS operation) based on another distribution key, if you think that the other key is better
- When talking about query performance, statistics are also very important for the query optimizer to generate a good query plan. Make sure your statistics are always up to date.
In most cases you’re best advised to look for a column with a high number of distinct values. If you know that you frequently need to join this to another distributed table, take this into account (join key is a candidate for the distribution key if it has a high enough cardinality). In some rare cases you may want to create pre-aggregated tables (to have more queries being aggregation compatible) or keep multiple versions of the same distributed table with different distribution keys. But again, in most cases finding a good distribution is not rocket science and you will be surprised how well the PDW works even with distribution keys being not optimal.


Kommentare (0)