SQL Server 2005 | SQL Server 2008
This post is about a common error message during dimension processing I’ve been asked about quite a few times so I thought it would be worth posting about it. The error message says that a duplicate attribute key has been found when processing as shown in the following screenshot for a test cube (I just processed one dimension here):
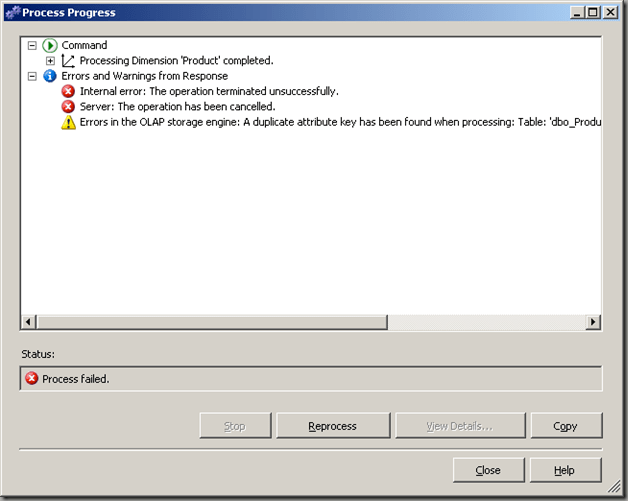
Here’s the full error message:
-
Errors in the OLAP storage engine: A duplicate attribute key has been found when processing: Table: ‚dbo_Product‘, Column: ‚ProductGroup‘, Value: “. The attribute is ‚Product Group‘.
When you got to this article because you just ran into this problem you probably don’t want to read much about the background but only want a solution. Unfortunately I found at least three possible reasons for this error message:
Reason 1 (likely): The most likely reason for that error is that you are having NULL values in your attribute key column.If you simply created the attribute by dragging it from the source view, BIDS only sets the key column (name and value column default to the key column in this case), so for example if you have a column ‘Product Group’ in your source table and drag it to your dimension, the product group (Text field) will automatically become the key for this attribute. The attribute is listed in the error message (in the example above it is ‘Product Group’).
Solution: Try avoiding those NULL values in your data source (for example by using a DSV query and the T-SQL coalesce-function). When your source data is a data warehouse it’s also a good practice to avoid null values as they complicate the queries to the data warehouse.
Reason 2 (likely): You defined an attribute relationship between two attributes of the dimension but the data in your source tables violates the relationship. The error message gives you the name of the conflicting attribute (text part ‘The attribute is…’). The attributes has a relationship to another attribute but for the value stated in the error message (‘Value: …’) there are at least two different values in the attribute that the relationship refers to. If you have BIDS Helper installed, you can also see the error details and all violating references when using the ‘Dimension Health Check’ function.
Solution: You may solve the error by making the key of the attribute unique. For example:
Errors in the OLAP storage engine: A duplicate attribute key has been found when processing: Table: ‚DimDate_x0024_‘, Column: ‚Month‘, Value: ‚April‘. The attribute is ‚Month‘.
In this example, the Month attribute violates an attribute relationship (maybe Month->Year) for the month April meaning that April appears for more than one year. By adding the year to the key of the month attribute you would make the relationsship unique again.
Reason 3 (not that likely): You have an attribute with separate key and name source fields. When you check the data, you see that keys are appearing more than once with different entries in their name columns (note that it’s not a problem if the key appears more than once if only the name column is the same). In this case you will usually also see the key value in the error message, for example:
Errors in the OLAP storage engine: A duplicate attribute key has been found when processing: Table: ‚dbo_Product2‘, Column: ‚ProductCode‘, Value: ‚1‘. The attribute is ‚Product Name‘.
This means that the attribute ‘Product Name’ uses the source column ‘ProductCode’ as the key and for the product code 1 there is more than one name.
Solution: Use a unique key column (unique with respect to the name column)
Long explanation Reason 1:
In this case our attribute is only defined by one single source column (acting as key, name and value information) from the data source view. When processing a dimension, SSAS run select distinct queries on the underlying source table, so a duplicated key should be impossible even if the key appears multiple times. Just think of a date dimension like the following one (just for years and months):
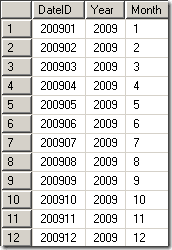
In this case the year (2009) appears in multiple rows. However, defining an attribute year (using the the year column as the key) does not give a conflict as it is queried using a distinct query (so 2009 only appears once). So again, how could we get a duplicate result when using a select distinct query? Here is how my product table looked like:
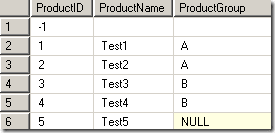
As you can see the ProductGroup column has one row with an empty string and another row with a NULL value. When SSAS queries this attribute during processing it runs the following SQL query (that can be captured using the profiler):
-
SELECT DISTINCT [dbo_Product].[ProductGroup] AS [dbo_ProductProductGroup0_0]
-
FROM [dbo].[Product] AS [dbo_Product]
The result of the query looks like this:
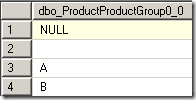
Now, with the default NULL processing for our dimension attribute being set to ‘Automatic’ meaning Zero (for numerical values) or Blank (for texts) the NULL value above is converted to an empty string. So the result set has two lines with an empty string and that causes the error.
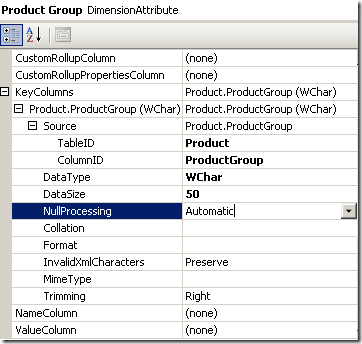
So the problem can be avoided if you don’t have null values in your column. This explains the first reason described above.
Long explanation Reason 2:
I blogged about attribute relationship before and you may want to read this post about defining the key for attributes in an attribute relationship.
Long explanation Reason 3:
Let’s take a look at the following modified product table.
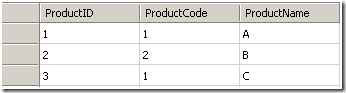
The ProductID column is unique while the ProductCode is not. If we now define the ProductName attribute as follows we will also get a duplicate key error:

The reason here is that for the ProductCode 1 two names are found (and therefore the select distinct returns two lines with ProductCode 1), so ProductCode is not a good key here. The problem would disappear if the ProductName for the third line would also be ‘A’ (like for the first line) or the ProductCode for the third line would be other than 1 or 2.
However, this reason occurs rather seldom because usually if we have a key and a name in our dimension, the source comes from some kind of master data table and therefore it should be unique. But for type 2 slowly changing dimensions you must not use the business key as key column (as there may be many rows with the same business key).
Another way to “solve” duplicate key errors (although not recommended) is to set the “KeyDuplicate” property for the error processing of the dimension to “IgnoreError” as shown below:
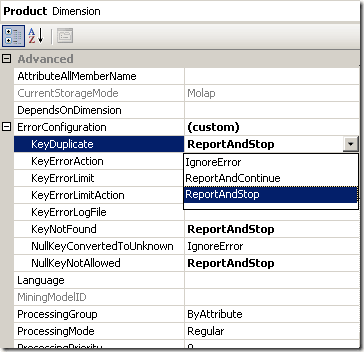
However, this is definitely not recommended except for prototyping scenarios.





Kommentare (0)