dimensional modeling
When it comes to dimension design a common question is about dealing with attributes that are changing over time. A frequently used pattern for such attributes was developed by Ralph Kimball with his concept of slowly changing dimensions (SCD). One aspect is to handle source systems that simply overwrite their master data, while you want to preserve past attribute properties for your analytics. I’m not going in to too much detail here, but focus on the 2 most important types:
Type 1:changes are directly overwritten in the dimension table. Past values are not preserved but get lost
Type 2: Past values for dimension data is kept using date from/to columns and/or a current row indicator
There are more types and also combinations of types (hybrid types). You can find much more about slowly changing dimensions here
.
When talking to other BI architects I frequently hear the opinion that type 2 should be used for almost every attribute. I wouldn’t agree to this statement and try to use SCD type 1 wherever it is possible and type 2 only, if there is a real business requirement for type 2. To be clear, there’s nothing wrong with type 2, but it adds a significant complexity to your BI solution and in some cases, also has other downsides to be aware of. This post collects 7 topics that you should know about when deciding for type 1, type 2 or any other method for dealing with historical values.
1. Corrections versus historically relevant changes
Usually, we don’t want corrections, like a typo in a customer’s name, to be kept historically. For example, if a customer’s name was corrected from ‘Miler Inc.’ to ‘Miller Inc.’, usually we don’t want to see this as two different customers in our reports:
Instead of
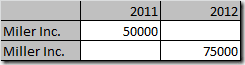
we want to see

However, if the Miller Inc. consolidates with Hiller Inc. to “Miller & Hiller Inc.”, we might want to see them as separate customers, for example like this:
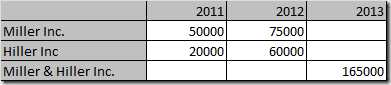
So, the problem with corrections is obvious. When a change of data happens in the source system, we might not be able to distinguish corrections from changes that need to be preserved over time. One option could be to use a function like soundex to treat minor changes to such a field as a type 1 modification (to the most current type 2 entry) and all others as a type 2 change. For the example from above, “Miler Inc.” and “Miller Inc.” both result in soundex code “M460”. But using soundex (or a similar function) does not guarantee us to get the result we wanted, i.e. to decide between corrections and modifications at a reliable rate, it’s still just a guess.
So it’s much more common to treat attributes/fields where we expect more corrections as SCD-1 and attributes that rather experience structural changes as SCD-2. Again, this does not necessarily guarantee to be correct.
In many cases where we need SCD-2, a good approach is the following:
- If we only have a text-field, make it SCD-1
- If we have a key/value field (because the value is taken from another table), make it a
- SCD-2 change, if the key changes
- SCD-1 change, if the text for that key changes
In special cases, things might be more complicated. For example, if you have ZIP code and city, a change to the ZIP code alone may rather be an SCD-1 change (more likely to be a correction), while a change in the ZIP code and the city name more likely indicates a relocation and therefore results in an SCD-2 change.
In any way, we’re trying to guess the idea the user had, when doing the modification, just by looking at the result.
2. Comparing with data from the past
When the requirement is to compare current data with data from the past, it seems to be obvious that we need SCD-2 to preserve the correct dimension structures from the past. But is this really true? Well, actually it depends on what you need the analysis for. For example, take a look at the following chart, showing sales of a specific product group.

First thing to note is that this chart breaks a lot of information design rules. In this chart confusion is intensified with a faked continuity by using a line chart (shame on me). The line chart here obfuscates the real situation by showing a continuous descent in September while actually the value is falling instantly here. Now, what can you say when looking at this line chart?
- The product group performed ok between January and September
- September was a great month
- Between September and October a catastrophe must have happened. Maybe a competitor launched better and cheaper products or there were reasons to cause a bad publicity
And how would an end user react, if you say that all this is not true? The descent in October is nothing but a SCD-2 change (a what?) as one major product was moved to a different product group. In fact nothing happened, not a catastrophe, no competitor being better, just a change in the master data. This is a typical situation with SCD-2 changes over time: Results are not self-explaining and may cause jerky leaps when data is plotted over time.
If the product hierarchy was maintained as SCD-1, maybe the chart would look like the green line below:
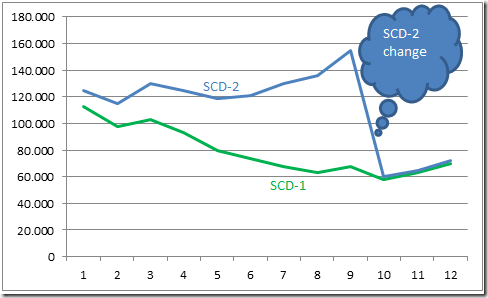
I think you can clearly see the advantage. The green line (SCD-1) is free of SCD-2 leaps, so it’s much easier to understand for the end-users. The interpretation is more like:
- We had some problems between January and October
- but we managed a turn-around in November and December
So, whenever you like to see trends, derive insight for future development or find outliers, the SCD-1 view is much easier to understand without additional explanation about master data changes.
3. Mixture of different concepts (type 1, type 2 …)
Maybe we don’t want all attributes to be type 2. The requirement could be that some hierarchies are on type 2 while others are on type 1. Again, think about the end users. Mixing both concepts may be very confusing. In some aspects you may be able to compare with printed reports from the past, in some aspects data is shown differently. However, making all attributes type 2 is also a problem (see ‘corrections’ above). One option might be to use perspectives: One perspective for the current type-1 view, one for the past type-2 view. However, another option would be to question if you really need the type-2 view, especially in a mixed form.
4. Justification or reproduction of results from the past
The requirement for keeping dimensional data in its historical form (past view, type-2) often results from the need for justification. If we want to be able to reproduce results in the same way as they were at some point of time in the past, we need to keep track of changes. Maybe someone asks you why you haven’t already seen the sales problems from our example from above (green line) in April. With the SCD-2 type of the chart (blue line from above), you could prove that the chart for April was still fine, so obviously you’re not responsible for the mess (this doesn’t solve the problem, but maybe a good justification). Other reasons to reproduce a report with exactly the same values from the past, are compliance reasons (SOX, BASEL II etc.). However, if you build your BI solution to justify yourself, keep in mind:
- Keeping historical values for the dimensions is not sufficient in most cases
- Fact data may have been corrected or may not have been available at the time the report was generated in the past
So, often enough, you also need to preserve the historical state of your fact data. Maybe you end up with a separate key date dimension to show the data exactly as it was at this point in time. Besides the need for keeping the historical state of all attributes in all dimensions (even for corrections!), this may also raise the complexity and costs of your BI-system significantly. So, if you don’t have these requirements, there is no reason to implement this historical view.
5. What is the “real” time of the change?
If we have virtual structures that only exist in some master data system, that are only maintained there and that are not delimited in time (valid date from/to), the SCD-2 detection usually works as expected. This might be true for typical objects in controlling, a cost center hierarchy or a profit center. In other cases, the time of change in the master data system, must not necessarily match the real time of the change. Think of a senior sales manager. A very important customer was assigned to the sales manager at the beginning of the year. Then the sales manager wins a big deal with this customer. But the BI system doesn’t show the revenue associated to this sales manager. What went wrong? Usually, the sales manager wants to know in such a situation. Let’s assume, the customer relationship department simply forgot to move the customer over to the new sales manager. After being notified they immediately correct this error. But then? If the BI system has no valid from/to date information from the source system, it is only capable of observing the date where the change occurred. Data from the past will still be associated to the wrong sales manager, usually causing trouble and confusion. Of course, there is no simple solution for this case. If you don’t have a proper valid date range from the source system, this issue can only be solved by manually correcting this case. The thing, I want to point out here, is that SCD-2 alone might not be able to solve such situations as it is impossible to guess the real date for a change from observing the change in a master data table.
6. Persisted data in BI-system
Of course it’s normal to persist data in the data warehouse system. But many smaller BI systems don’t need to do that, as all data is available in some source systems. This situation has some benefits. For example it’s easy to include other topics of data for the full history (complete re-load). Also, there is no need to back-up the data warehouse. So, if you are in such a good situation and a requirement is to include SCD-2 while the source system simply overwrites its data, you can no longer take all that data from the source system. Again, not much of a problem, but it adds some kind of complexity to you BI-system.
7. Testing
If the source system overwrites its data while the BI system maintains history in a SCD-2 style, it’s more difficult to test the results from you source system with the BI system as your source system can only report data in the most current state while you BI-system reports some (or all) attributes in the historic perspective. Now, testing is very important and in many cases you can even do automatic testing (using a tool like BI.Quality
). So, if you cannot reproduce the current state of the data from your BI-system, testing is very difficult. So for many situations, my recommendation is to use SCD-6 (1+2+3) instead of SCD-2 even if the SCD-1 view is not necessary but for testing purposes. Again, this adds complexity.
Conclusion
The concept of the slowly changing dimensions belongs to the fundament of BI data modeling. However, keeping historical values using type 2 (SCD-2) may have some negative side effects and raise the complexity of your BI system. So it’s a good advice to consider handling historical changes carefully and to be fully aware of those side effects.




Kommentare (0)